
What Is Underfitting in Machine Studying?
Underfitting is a typical subject encountered through the growth of machine studying (ML) fashions. It happens when a mannequin is unable to successfully study from the coaching information, leading to subpar efficiency. On this article, we’ll discover what underfitting is, the way it occurs, and the methods to keep away from it.
Desk of contents
What’s underfitting?
Underfitting is when a machine studying mannequin fails to seize the underlying patterns within the coaching information, resulting in poor efficiency on each the coaching and take a look at information. When this happens it signifies that the mannequin is simply too easy and doesn’t do a superb job of representing the information’s most essential relationships. Consequently, the mannequin struggles to make correct predictions on all information, each information seen throughout coaching and any new, unseen information.
How does underfitting occur?
Underfitting happens when a machine studying algorithm produces a mannequin that fails to seize an important properties of the coaching information; fashions that fail on this approach are thought of to be too easy. As an illustration, think about you’re utilizing linear regression to foretell gross sales based mostly on advertising spend, buyer demographics, and seasonality. Linear regression assumes the connection between these elements and gross sales will be represented as a mixture of straight strains.
Though the precise relationship between advertising spend and gross sales could also be curved or embrace a number of interactions (e.g., gross sales rising quickly at first, then plateauing), the linear mannequin will oversimplify by drawing a straight line. This simplification misses essential nuances, resulting in poor predictions and general efficiency.
This subject is frequent in lots of ML fashions the place excessive bias (inflexible assumptions) prevents the mannequin from studying important patterns, inflicting it to carry out poorly on each the coaching and take a look at information. Underfitting is usually seen when the mannequin is simply too easy to characterize the true complexity of the information.
Underfitting vs. overfitting
In ML, underfitting and overfitting are frequent points that may negatively have an effect on a mannequin’s means to make correct predictions. Understanding the distinction between the 2 is essential for constructing fashions that generalize effectively to new information.
- Underfitting happens when a mannequin is simply too easy and fails to seize the important thing patterns within the information. This results in inaccurate predictions for each the coaching information and new information.
- Overfitting occurs when a mannequin turns into overly complicated, becoming not solely the true patterns but in addition the noise within the coaching information. This causes the mannequin to carry out effectively on the coaching set however poorly on new, unseen information.
To raised illustrate these ideas, take into account a mannequin that predicts athletic efficiency based mostly on stress ranges. The blue dots within the chart characterize the information factors from the coaching set, whereas the strains present the mannequin’s predictions after being educated on that information.

1
Underfitting: On this case, the mannequin makes use of a easy straight line to foretell efficiency, despite the fact that the precise relationship is curved. For the reason that line doesn’t match the information effectively, the mannequin is simply too easy and fails to seize essential patterns, leading to poor predictions. That is underfitting, the place the mannequin fails to study essentially the most helpful properties of the information.
2
Optimum match: Right here, the mannequin matches the curve of the information appropriately sufficient. It captures the underlying development with out being overly delicate to particular information factors or noise. That is the specified state of affairs, the place the mannequin generalizes moderately effectively and may make correct predictions on comparable, new information. Nonetheless, generalization can nonetheless be difficult when confronted with vastly totally different or extra complicated datasets.
3
Overfitting: Within the overfitting state of affairs, the mannequin intently follows virtually each information level, together with noise and random fluctuations within the coaching information. Whereas the mannequin performs extraordinarily effectively on the coaching set, it’s too particular to the coaching information, and so will probably be much less efficient when predicting new information. It struggles to generalize and can possible make inaccurate predictions when utilized to unseen situations.
Widespread causes of underfitting
There are lots of potential causes of underfitting. The 4 most typical are:
- Mannequin structure is simply too easy.
- Poor characteristic choice
- Inadequate coaching information
- Not sufficient coaching
Let’s dig into these a bit additional to grasp them.
Mannequin structure is simply too easy
Poor characteristic choice
Inadequate coaching information
Not sufficient coaching
Coaching an ML mannequin includes adjusting its inner parameters (weights) based mostly on the distinction between its predictions and the precise outcomes. The extra coaching iterations the mannequin undergoes, the higher it could possibly regulate to suit the information. If the mannequin is educated with too few iterations, it might not have sufficient alternatives to study from the information, resulting in underfitting.
The way to detect underfitting
Within the case of underfitting, you’ll discover the next key patterns:
- Excessive coaching loss: If the mannequin’s coaching loss stays excessive and flatlines early within the course of, it means that the mannequin shouldn’t be studying from the coaching information. It is a clear signal of underfitting, because the mannequin is simply too easy to adapt to the complexity of the information.
- Related coaching and validation loss: If each the coaching and validation loss are excessive and stay shut to one another all through the coaching course of, it means the mannequin is underperforming on each datasets. This means that the mannequin shouldn’t be capturing sufficient info from the information to make correct predictions, which factors to underfitting.
Beneath is an instance chart displaying studying curves in an underfitting state of affairs:
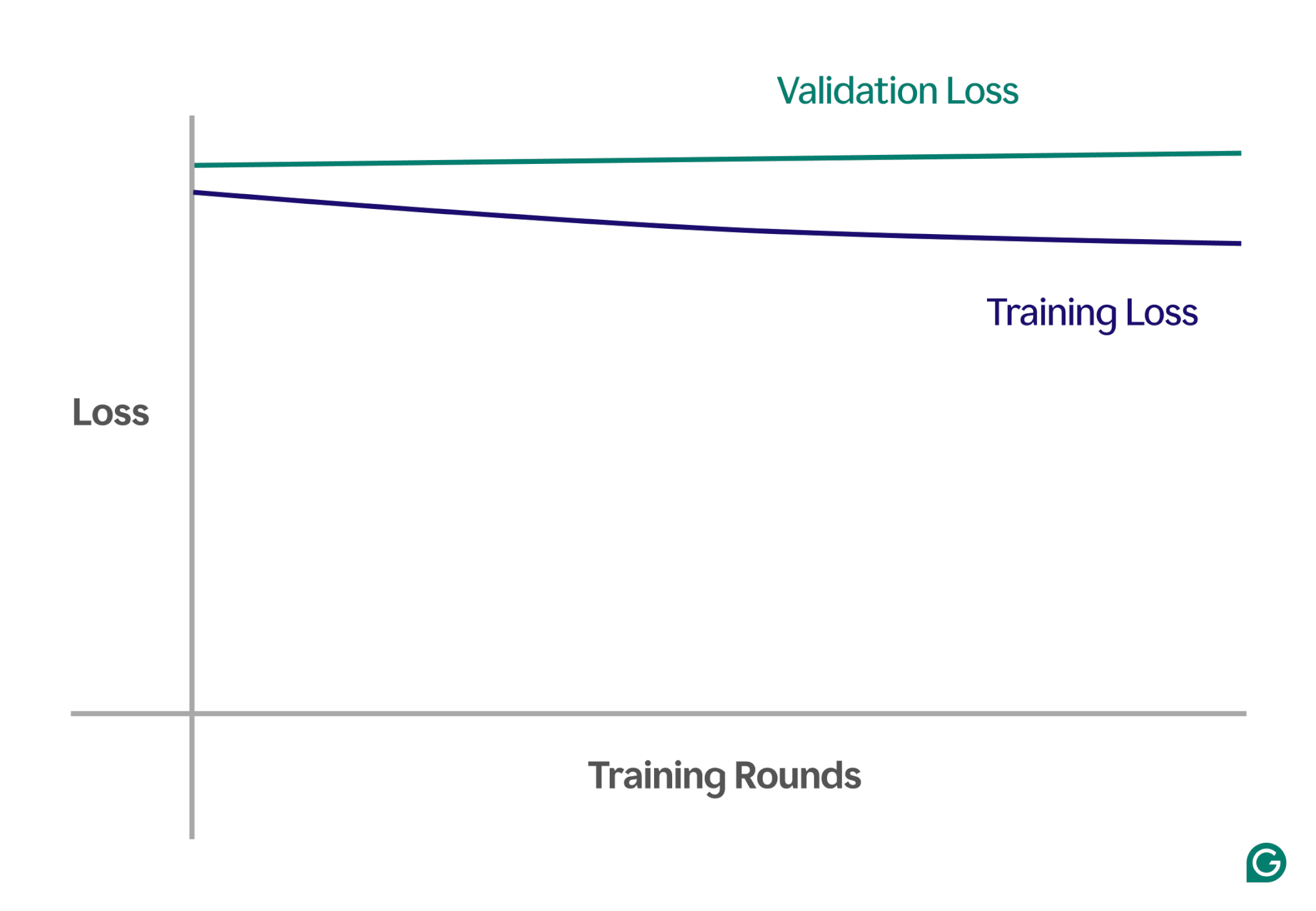
On this visible illustration, underfitting is straightforward to identify:
- In a well-fitting mannequin, the coaching loss decreases considerably whereas the validation loss follows an identical sample, ultimately stabilizing.
- In an underfitted mannequin, each the coaching and validation loss begin excessive and keep excessive, with none vital enchancment.
By observing these traits, you may rapidly establish whether or not the mannequin is simply too simplistic and desires changes to extend its complexity.
Methods to forestall underfitting
- Extra coaching information: If attainable, get hold of further coaching information. Extra information offers the mannequin further alternatives to study patterns, supplied the information is of top quality and related to the issue at hand.
- Develop characteristic choice: Add to the mannequin options which are extra related. Select options which have a robust relationship to the goal variable, giving the mannequin a greater likelihood to seize essential patterns that had been beforehand missed.
- Improve architectural energy: In fashions based mostly on neural networks, you may regulate the architectural construction by altering the variety of weights, layers, or different hyperparameters. This could permit the mannequin to be extra versatile and extra simply discover the high-level patterns within the information.
- Select a special mannequin: Generally, even after tuning hyperparameters, a particular mannequin is probably not effectively suited to the duty. Testing a number of mannequin algorithms can assist discover a extra applicable mannequin and enhance efficiency.
Sensible examples of underfitting
For example the results of underfitting, let’s take a look at real-world examples throughout numerous domains the place fashions fail to seize the complexity of the information, resulting in inaccurate predictions.
Predicting home costs
To precisely predict the value of a home, you might want to take into account many elements, together with location, measurement, sort of home, situation, and variety of bedrooms.
In case you use too few options—corresponding to solely the dimensions and kind of the home—the mannequin gained’t have entry to crucial info. For instance, the mannequin would possibly assume a small studio is cheap, with out figuring out it’s positioned in Mayfair, London, an space with excessive property costs. This results in poor predictions.
To resolve this, information scientists should guarantee correct characteristic choice. This includes together with all related options, excluding irrelevant ones, and utilizing correct coaching information.
Speech recognition
Voice recognition expertise has turn out to be more and more frequent in day by day life. As an illustration, smartphone assistants, customer support helplines, and assistive expertise for disabilities all use speech recognition. When coaching these fashions, information from speech samples and their right interpretations are used.
To acknowledge speech, the mannequin converts sound waves captured by a microphone into information. If we simplify this by solely offering the dominant frequency and quantity of the voice at particular intervals, we cut back the quantity of knowledge the mannequin should course of.
Nonetheless, this method strips away important info wanted to totally perceive the speech. The info turns into too simplistic to seize the complexity of human speech, corresponding to variations in tone, pitch, and accent.
Consequently, the mannequin will underfit, struggling to acknowledge even primary phrase instructions, not to mention full sentences. Even when the mannequin is sufficiently complicated, the shortage of complete information results in underfitting.
Picture classification
A picture classifier is designed to take a picture as enter and output a phrase to explain it. Let’s say you’re constructing a mannequin to detect whether or not a picture accommodates a ball or not. You practice the mannequin utilizing labeled photos of balls and different objects.
In case you mistakenly use a easy two-layer neural community as an alternative of a extra appropriate mannequin like a convolutional neural community (CNN), the mannequin will wrestle. The 2-layer community flattens the picture right into a single layer, shedding essential spatial info. Moreover, with solely two layers, the mannequin lacks the capability to establish complicated options.
This results in underfitting, because the mannequin will fail to make correct predictions, even on the coaching information. CNNs clear up this subject by preserving the spatial construction of photos and utilizing convolutional layers with filters that robotically study to detect essential options like edges and shapes within the early layers and extra complicated objects within the later layers.




