
AI-Powered Writing Help throughout A number of Languages
The Strategic Analysis staff at Grammarly is continually exploring how LLMs can contribute to our mission of enhancing lives by enhancing communication. Our earlier work on CoEdIT confirmed that LLMs skilled particularly for textual content modifying will be of upper high quality and extra performant. We targeted our experiments on English. Nevertheless, most foundational fashions produced since our earlier work (from 2024 and on) have been multilingual. They will perceive directions and have conversations in a number of languages. And this had us questioning: What would it not take to assist a number of languages with CoEdIT?
Overview
With mEdIT, we lengthen CoEdIT to assist directions in seven languages, each when the directions match the language of the textual content and after they don’t. In our work on mEdIT, we use fine-tuning strategies much like those we used for CoEdIT to provide multilingual writing assistants which are a lot better than earlier ones. These assistants are efficient even when the language of the directions doesn’t match the language of the textual content (cross-lingual), can carry out a number of sorts of modifying duties (multi-task), and do effectively even for some languages they haven’t particularly been skilled for (generalizable).
Our work constructing CoEdIT and different analyses has proven that standard foundational LLMs produce low-quality outputs when requested to carry out textual content edits. Earlier makes an attempt to fine-tune LLMs for modifying duties have targeted on supporting both a number of modifying duties for a single language (virtually all the time English), or a single modifying activity throughout a number of languages. Only a few experiments have explored supporting a number of modifying duties concurrently. Our work improves on the constraints of prior work by:
- Supporting a number of modifying duties
- Accepting edit directions in a number of languages
- Taking edit directions in languages that don’t match the edited textual content
Our fashions obtain sturdy efficiency throughout a number of languages and modifying duties. By cautious experimentation, we offer insights into how varied decisions have an effect on mannequin efficiency on these duties, together with mannequin structure, mannequin scale, and coaching information mixtures. This put up summarizes how we went about this work, printed in our paper “mEdIT: Multilingual Textual content Enhancing by way of Instruction Tuning” at NAACL 2024.

Determine 1: mEdIT is multilingual and cross-lingual
Our information and fashions are publicly out there on GitHub and Hugging Face. By making our information and fashions publicly out there, we hope to assist make advances in multilingual clever writing assistants.1
What we did
We adopted a course of much like the one we used for CoEdIT. We fine-tuned a number of differing types and sizes of LLMs, so we might take a look at how mannequin measurement and structure selection influence efficiency.
We determined to cowl three totally different modifying duties: grammatical error correction (GEC), textual content simplification, and paraphrasing. These duties have comparatively well-defined analysis metrics and publicly out there human-annotated coaching information masking a variety of languages. Our coaching information for these duties included greater than 2 hundred thousand pairs of directions and rewrite outputs, all curated from publicly out there information units. See Determine 2 for a comparability of obtainable coaching information by language and edit activity.
We selected to work with seven languages, which lined six various language households. Moreover guaranteeing broad protection in our choice, we additionally chosen languages that had sufficient publicly out there human-annotated texts. We constructed mEdIT by fine-tuning a number of multilingual LLMs on fastidiously curated corpora from these publicly out there datasets (see the efficiency part under or our paper for full particulars). We selected Arabic, Chinese language, English, German, Japanese, Korean, and Spanish because the languages for this work.
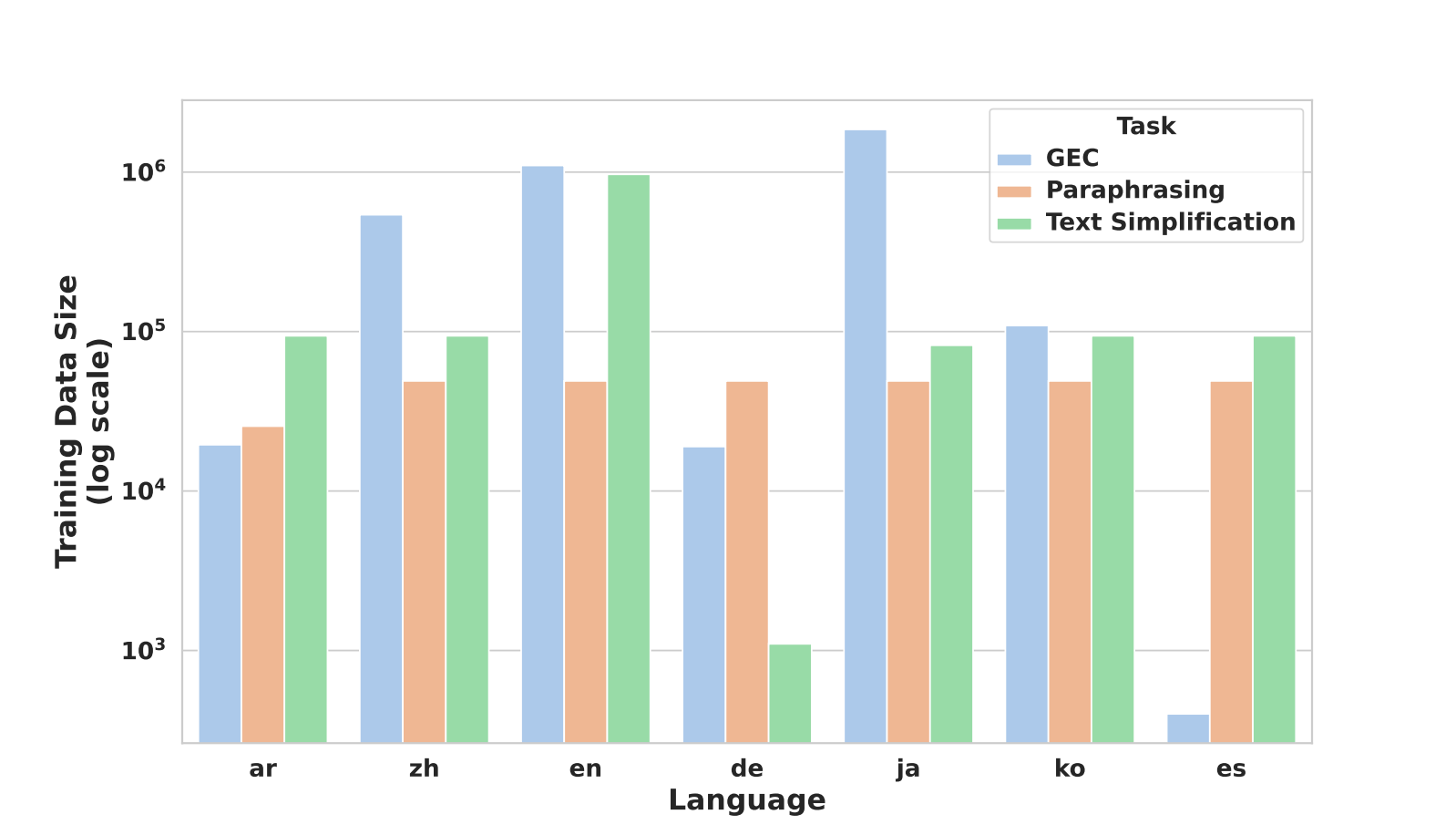
Determine 2: Relative measurement of obtainable coaching information by language and edit activity
Constructing the instruction-tuning dataset
To fine-tune the edit directions, we checked out 21 combos, supporting all three edit duties for every of the seven languages in our coaching set. To verify our directions had been correct, we requested native language audio system to overview and proper translated directions after they had been routinely generated from English variations.
We ready the info for every edit activity, together with randomly sampling 10K samples from every dataset (apart from Spanish GEC, the place we solely had 398 information factors). This selection optimizes computational value towards efficiency, based mostly on insights from our work on CoEdIT and follow-up experiments exhibiting high quality doesn’t enhance noticeably as a perform of information measurement; it improves as a perform of information high quality as a substitute.
Coaching the fashions
We fine-tuned two forms of mannequin architectures: encoder-decoder/sequence-to-sequence (Seq2Seq) and decoder-only/causal language fashions (CLM) on the mEdIT dataset. The Seq2Seq fashions included mT5 (Xue et al., 2021) and mT0 (Raffel et al., 2020), with parameter sizes between 1.3B and 13B. For CLM we used BLOOMZ (Muennighoff et al., 2023), PolyLM (Wei et al., 2023), and Bactrian-X (Li et al., 2023) fashions—with mannequin sizes starting from 2B to 13B. All of those multilingual fashions had been fine-tuned with our tutorial information set on 8xA100 80G GPU cases.
Efficiency
We used present normal analysis metrics for the three edit duties:
GEC: We adopted prior work, utilizing the suitable metrics for every language—one of many MaxMatch (M2) Scorer (Dahlmeier and Ng, 2012), ERRANT (Bryant et al., 2017), and GLEU (Napoles et al., 2015, 2016). For languages evaluated with both the M2 scorer or ERRANT, we used the F0.5 measure.
Simplification: We used SARI (Xu et al., 2016a) and BLEU (Papineni et al., 2002) for analysis, following work achieved by Ryan et al. (2023). SARI correlates with human judgments of simplicity, and BLEU is a typical machine translation metric that we used as a proxy for evaluating fluency and that means preservation towards references.
Paraphrasing: We used Self-BLEU (Zhu et al., 2018) to guage range relative to the supply textual content, and mUSE (Yang et al., 2020) to guage semantic similarity and that means preservation. We additionally thought of different standard metrics, similar to Multilingual-SBERT (Reimers and Gurevych, 2020) and LaBSE (Feng et al., 2022), however they had been unsuitable for our functions.
Multilingually skilled fashions outperform no matter instruction language
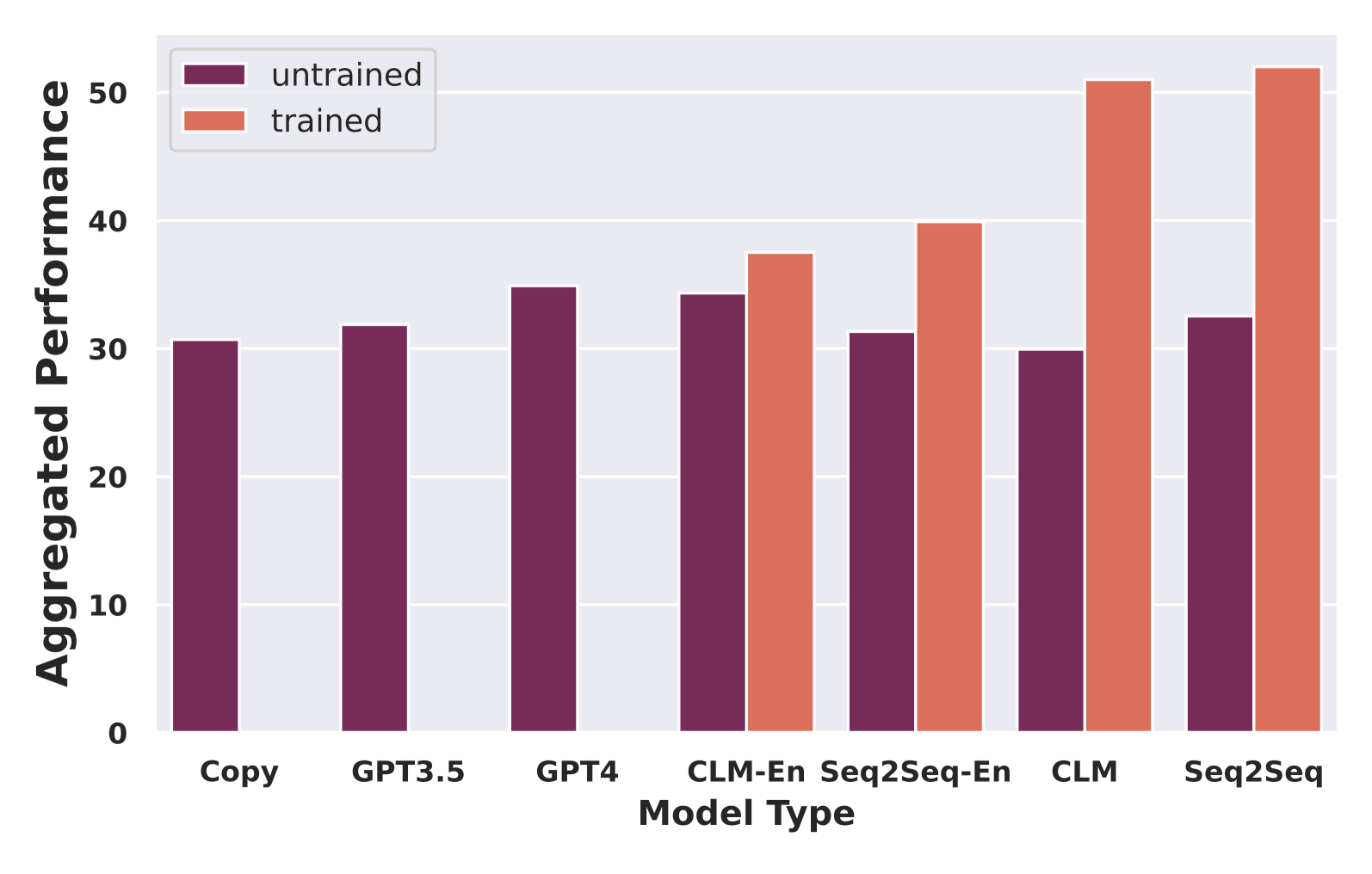
Determine 3: Efficiency of all baselines towards skilled fashions
To guage our work throughout instruction languages, first, we in contrast our work towards three totally different zero-shot baselines (copying enter to output, GPT3.5, and GPT4). We assessed two take a look at instances—a partial coaching case, with our fashions skilled simply on English directions (the -en suffix fashions in Determine 3 above), and a case the place our fashions had been skilled on the complete multilingual units. We calculated efficiency throughout all duties utilizing the harmonic imply of task-specific scores. A core contribution of our work is to push the efficiency of small- (~1B) to medium-sized LLMs (1-15B parameters) for widespread modifying duties throughout a number of languages, and we present a considerable enchancment over their untrained counterparts. Normally, fashions skilled with multilingual directions carry out a lot better than the remainder.
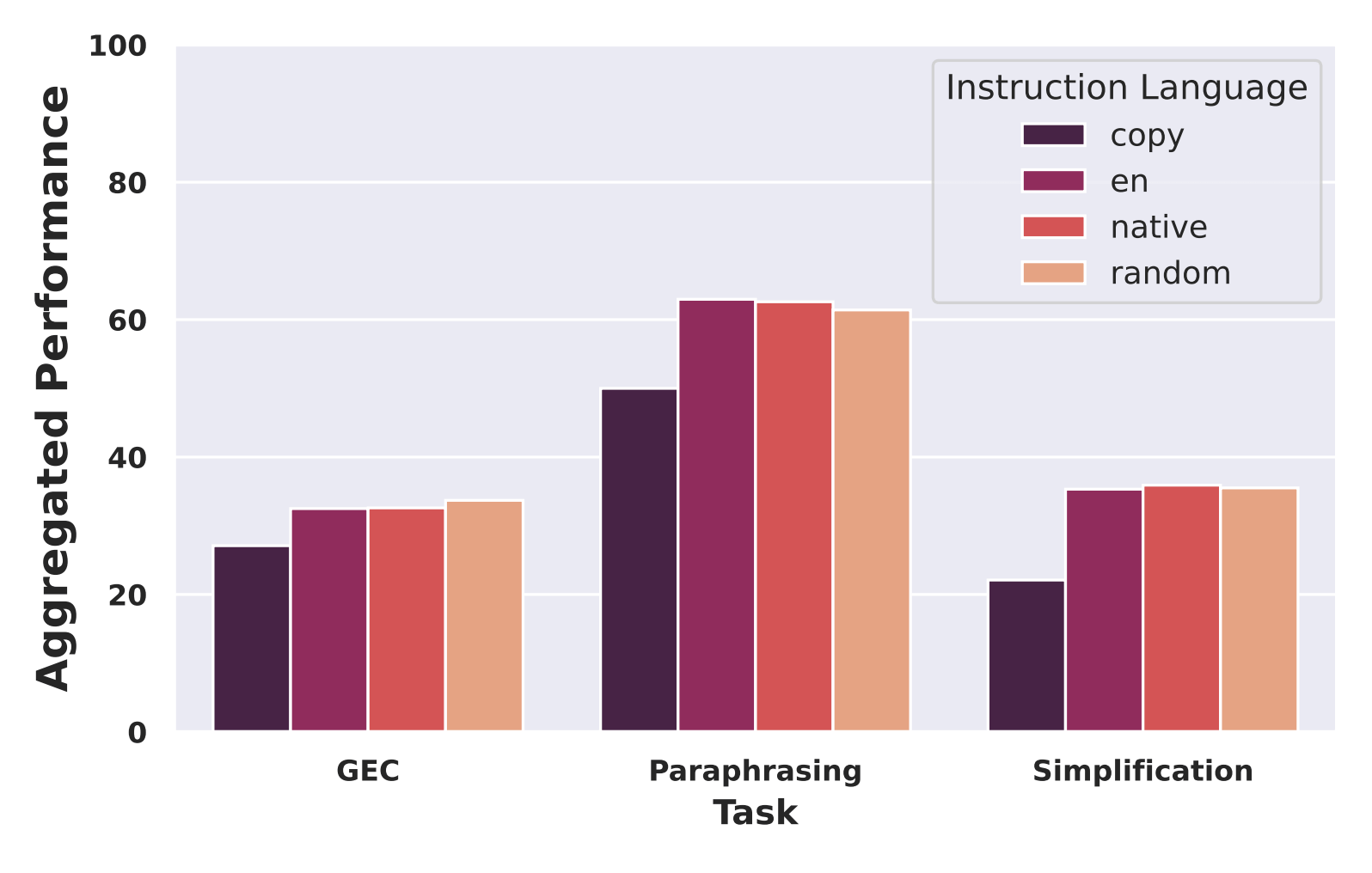
Determine 4: Aggregated efficiency on totally different duties damaged down by instruction language
To guage our work throughout the language of instruction, we ran 4 totally different units of experiments:
- No-edits: As a baseline, we evaluated copying the supply to the output and scored it.
- English: All directions to the fashions had been in English.
- Native: The directions matched the language of the textual content being edited.
- Random: The directions had been in a random language.
In mixture, efficiency was steady throughout our take a look at instances (see Determine 4). Fashions carried out on the identical excessive stage it doesn’t matter what language the directions had been in or whether or not the language matched the physique of the textual content. Probably it is a consequence of every mannequin’s multilingual educational pre-training, which ought to permit them to adapt effectively throughout the fine-tuning section.
Efficiency on edited language is correlated with out there coaching information
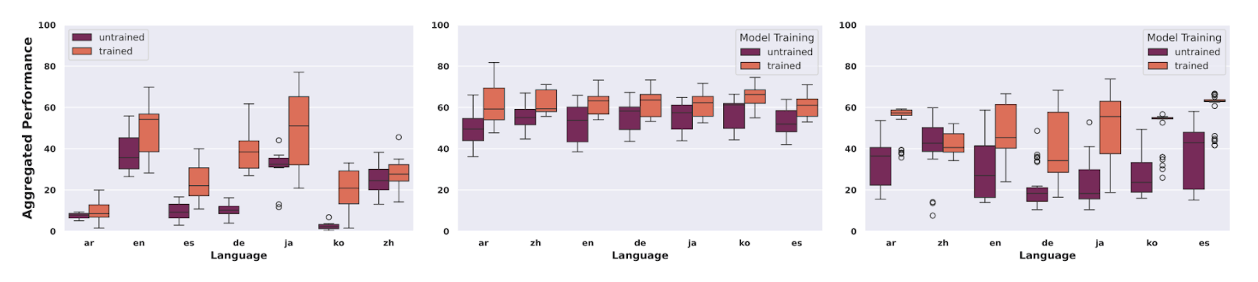
Determine 5: Combination mannequin efficiency by language (for GEC, Paraphrasing, and Simplification, respectively)
When grouped by edit activity, the variance in efficiency throughout languages is correlated with the quantity and high quality of information out there for every. German, for instance, with just one.1K information factors, confirmed each a really massive enchancment with high-quality tuning and a terrific variance in outcomes. We partially attribute the regular efficiency of Paraphrasing to the weak spot of the analysis metrics (they rely totally on n-gram overlap), to the big mannequin measurement and fine-tuning (bigger and extra tuned fashions are inclined to make fewer modifications), and to the multilingual pre-training of the LLMs the place they see medium-large corpora of almost all the languages—see Determine 5 for particulars.
mEdIT generalizes to unseen languages
For every activity, we examined our fashions on languages not seen throughout coaching—one language associated to the six language households we lined in coaching and one which wasn’t. These had been, nevertheless, languages that the underlying LLM had been pre-trained on, so the fashions did perceive them.
Once we evaluate the efficiency of mEdIT to the monolingual cutting-edge, it’s aggressive on a number of language-edit activity combos, particularly Simplification for Italian, and GEC and Paraphrasing for Hindi (see the desk under).
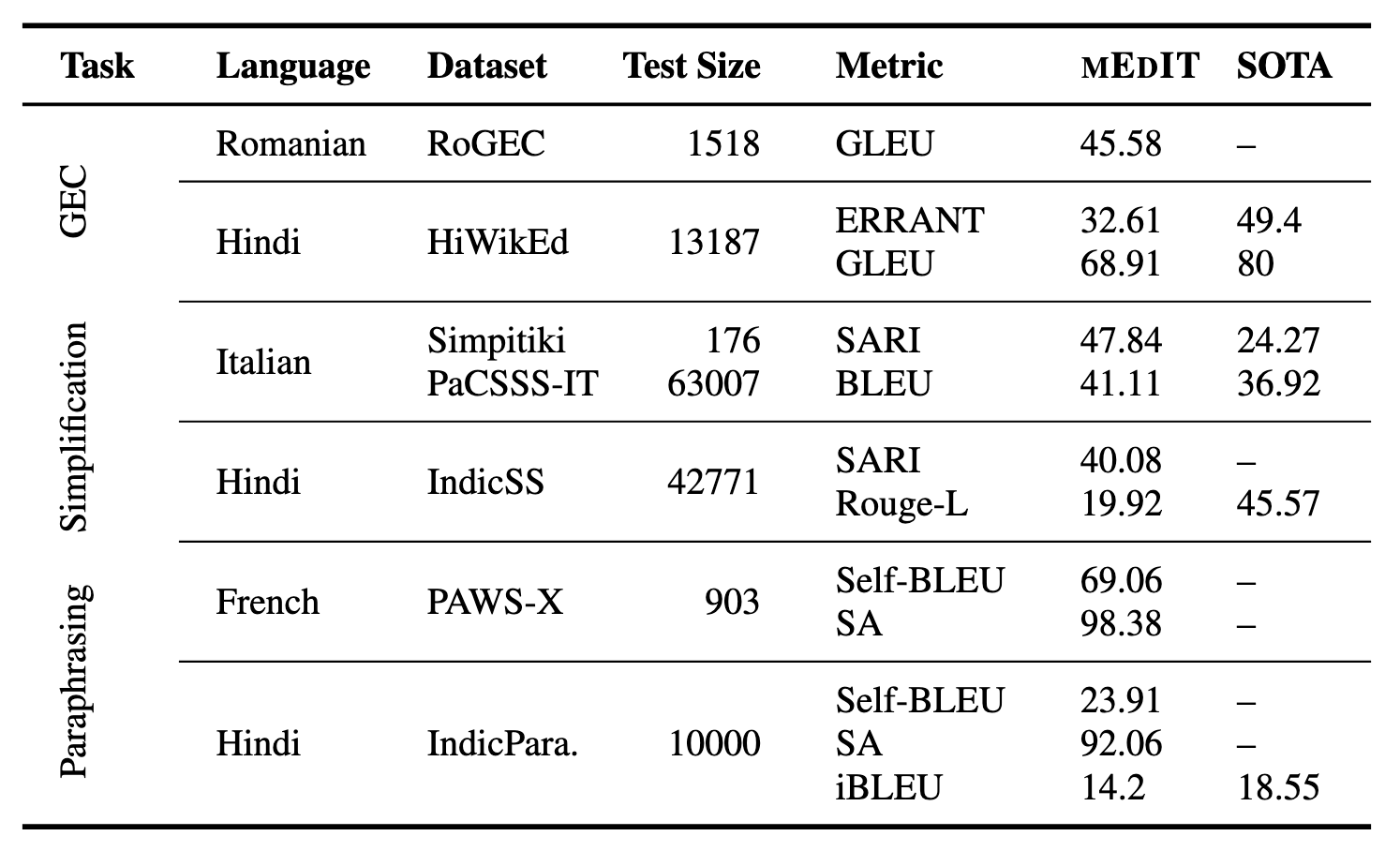
Desk 1: Outcomes from language generalization experiments
Coaching generalizes throughout edit duties
To measure the influence of particular person edit activity coaching on total efficiency, we systematically ablated parts of information for every activity and noticed how that impacted efficiency. As anticipated, decrease quantities of coaching information for a activity led to decrease efficiency on that particular activity. We observed, nevertheless, that the coaching interprets throughout duties, and typically coaching for one improves efficiency for an additional. Elevated coaching for GEC interprets into improved efficiency on simplification and paraphrasing, for instance. And the identical holds for the opposite duties.
CLMs carried out greatest, and efficiency elevated with mannequin measurement
When evaluated individually, CLMs both matched or exceeded the efficiency of all different fashions. Seq2Seq fashions have barely greater BLEU scores than CLMs on Simplification, which we suspect outcomes from Seq2Seq fashions producing shorter sequences typically.
Surprisingly, particularly contemplating GPT4’s multilingual capabilities, each GPT3.5 and GPT4 carried out poorly relative to the opposite fashions, with GPT3.5 performing the least effectively of all of the fashions we thought of. This can be an artifact of our metrics since GLEU depends on overlap with reference materials, and bolstered studying from human reference (RLHF) can produce wonderful outcomes that don’t overlap. Additional work into creating extra strong metrics would possibly present higher insights.
As anticipated, mannequin measurement is essential, and bigger fashions present considerably improved efficiency throughout all duties, particularly for GEC and Paraphrasing.
Human suggestions
We collected suggestions from professional annotators, utilizing a course of much like the method we adopted for the CoEdIT work. Within the desk under, we famous the share of our evaluators who chosen every analysis choice. In mixture, mannequin outputs obtained excessive scores throughout all languages. Mannequin suggestions for English, German, Chinese language, and Spanish was essentially the most optimistic. High quality was decrease for Arabic, which we consider outcomes from comparatively lower-quality coaching information for that language. Accuracy suffered for Chinese language, Japanese, Korean, and Spanish, and we nonetheless must work to enhance efficiency for these languages.
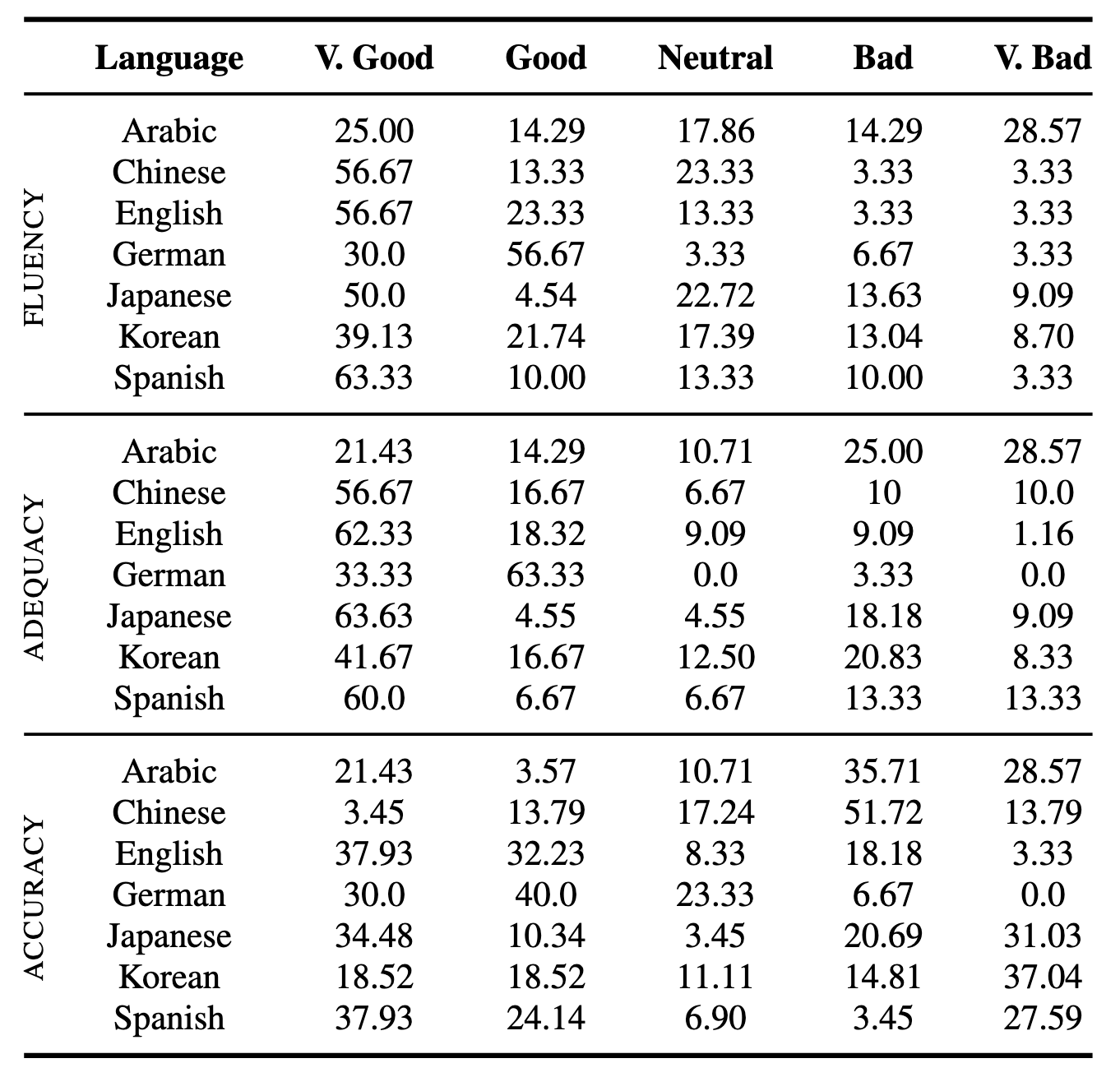
Desk 2: P.c frequency for every suggestions class obtained from human evaluators, aggregated by language
What’s subsequent?
With mEdIT, we’ve proven that LLMs can settle for edit directions in a single language and carry out these edits in a number of different languages. With cautious fine-tuning, these LLMs carry out a lot better than all different fashions constructed to this point. Optimistic suggestions from human evaluators means that mEdIT will assist them carry out edits at scale. The fine-tuned LLMs appear to generalize and work for languages and edit duties they haven’t been particularly fine-tuned for. We’ve made our work and information publicly out there within the mEdIT repository on GitHub and on Hugging Face to foster additional inquiry into the subject.
There’s much more work we’d do subsequent, to increase and construct on mEdIT:
- We might assist greater than seven languages and 6 language households—however that relies on having high-quality coaching information for these languages.
- We noticed the mannequin begin to generalize to languages it hasn’t seen, and people generalizations will be higher studied since they’ll result in extra accessible and ubiquitous writing assistants.
- We evaluated a small set of edit duties towards superficial measurements of success. We might go broader and deeper with our evaluations and, for instance, take a look at metrics for fluency, coherence, and that means preservation.
With efforts such because the extension of CoEdIT right into a multilingual mEdIT, we hope to transcend our core merchandise and contribute to our mission of enhancing lives by enhancing communication.
If that mission and fixing issues like these resonate with you, then we’ve excellent news: Grammarly’s Strategic Analysis staff is hiring! We’re keen about exploring and leveraging the potential of LLMs and generative AI to enhance writing and communication for everybody. Take a look at our open roles for extra info.
Word that Grammarly doesn’t incorporate this analysis into its product at present; whereas Grammarly is primarily targeted on providing writing assist in English, we’ve lately launched a translation characteristic for customers of different languages.


