
Learn how to Use F1 Rating in Machine Studying
The F1 rating is a robust metric for evaluating machine studying (ML) fashions designed to carry out binary or multiclass classification. This text will clarify what the F1 rating is, why it’s necessary, the way it’s calculated, and its functions, advantages, and limitations.
Desk of contents
What’s an F1 rating?
ML practitioners face a standard problem when constructing classification fashions: coaching the mannequin to catch all instances whereas avoiding false alarms. That is significantly necessary in crucial functions like monetary fraud detection and medical prognosis, the place false alarms and lacking necessary classifications have severe penalties. Reaching the fitting steadiness is especially necessary when coping with imbalanced datasets, the place a class like fraudulent transactions is far rarer than the opposite class (respectable transactions).
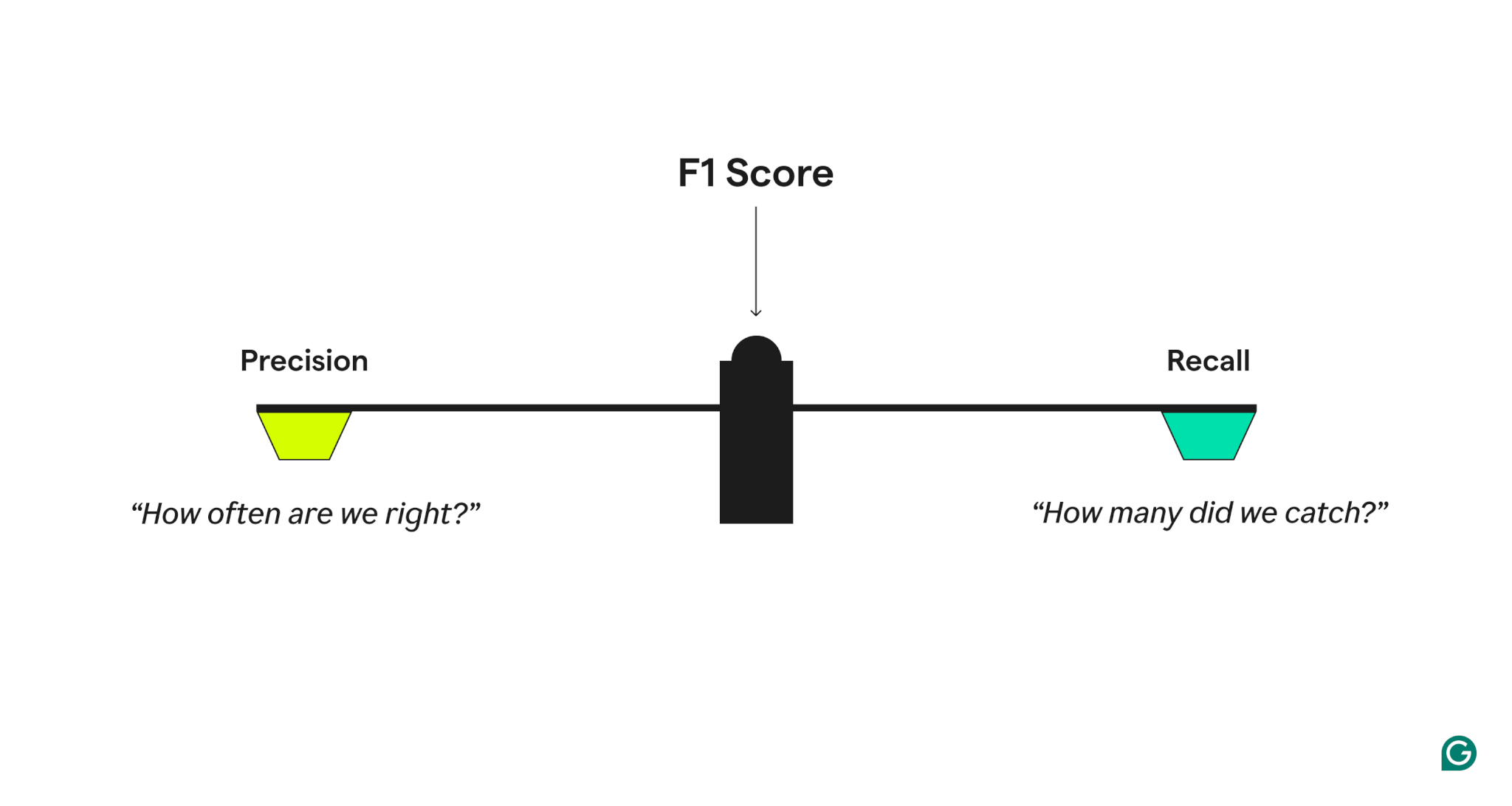
Precision and recall
To measure mannequin efficiency high quality, the F1 rating combines two associated metrics:
- Precision, which solutions, “When the mannequin predicts a optimistic case, how usually is it appropriate?”
- Recall, which solutions, “Of all precise optimistic instances, what number of did the mannequin appropriately establish?”
A mannequin with excessive precision however low recall is overly cautious, lacking many true positives, whereas one with excessive recall however low precision is overly aggressive, producing many false positives. The F1 rating strikes a steadiness by taking the harmonic imply of precision and recall, which provides extra weight to decrease values and ensures {that a} mannequin performs nicely on each metrics somewhat than excelling in only one.
Precision and recall instance
To raised perceive precision and recall, take into account a spam detection system. If the system has a excessive fee of appropriately flagging emails as spam, this implies it has excessive precision. For instance, if the system flags 100 emails as spam, and 90 of them are literally spam, the precision is 90%. Excessive recall, alternatively, means the system catches most precise spam emails. For instance, if there are 200 precise spam emails and our system catches 90 of them, the recall is 45%.
Variants of the F1 rating
In multiclass classification programs or eventualities with particular wants, the F1 rating might be calculated in several methods, relying on what elements are necessary:
- Macro-F1: Calculates the F1 rating individually for every class and takes the typical
- Micro-F1: Calculates recall and precision over all predictions
- Weighted-F1: Just like Macro-F1, however lessons are weighted based mostly on frequency
Past the F1 rating: The F-score household
The F1 rating is an element of a bigger household of metrics referred to as the F-scores. These scores supply other ways to weight precision and recall:
- F2: Locations higher emphasis on recall, which is helpful when false negatives are expensive
- F0.5: Locations higher emphasis on precision, which is helpful when false positives are expensive
Learn how to calculate an F1 rating
The F1 rating is mathematically outlined because the harmonic imply of precision and recall. Whereas this would possibly sound complicated, the calculation course of is simple when damaged down into clear steps.
The formulation for the F1 rating:

Earlier than diving into the steps to calculate F1, it’s necessary to know the important thing parts of what’s referred to as a confusion matrix, which is used to prepare classification outcomes:
- True positives (TP): The variety of instances appropriately recognized as optimistic
- False positives (FP): The variety of instances incorrectly recognized as optimistic
- False negatives (FN): The variety of instances missed (precise positives that weren’t recognized)
The final course of entails coaching the mannequin, testing predictions and organizing outcomes, calculating precision and recall, and calculating the F1 rating.
Step 1: Practice a classification mannequin
First, a mannequin have to be educated to make binary or multiclass classifications. Which means that the mannequin wants to have the ability to classify instances as belonging to certainly one of two classes. Examples embody “spam/not spam” and “fraud/not fraud.”
Step 2: Take a look at predictions and manage outcomes
Subsequent, use the mannequin to carry out classifications on a separate dataset that wasn’t used as a part of the coaching. Manage the outcomes into the confusion matrix. This matrix exhibits:
- TP: What number of predictions have been truly appropriate
- FP: What number of optimistic predictions have been incorrect
- FN: What number of optimistic instances have been missed
The confusion matrix offers an summary of how the mannequin is performing.
Step 3: Calculate precision
Utilizing the confusion matrix, precision is calculated with this formulation:

For instance, if a spam detection mannequin appropriately recognized 90 spam emails (TP) however incorrectly flagged 10 nonspam emails (FP), the precision is 0.90.

Step 4: Calculate recall
Subsequent, calculate recall utilizing the formulation:

Utilizing the spam detection instance, if there have been 200 complete spam emails, and the mannequin caught 90 of them (TP) whereas lacking 110 (FN), the recall is 0.45.

Step 5: Calculate the F1 rating
With the precision and recall values in hand, the F1 rating might be calculated.
The F1 rating ranges from 0 to 1. When decoding the rating, take into account these common benchmarks:
- 0.9 or greater: The mannequin is performing nice, however ought to be checked for overfitting.
- 0.7 to 0.9: Good efficiency for many functions
- 0.5 to 0.7: Efficiency is OK, however the mannequin might use enchancment.
- 0.5 or much less: The mannequin is performing poorly and wishes severe enchancment.
Utilizing the spam detection instance calculations for precision and recall, the F1 rating can be 0.60 or 60%.

On this case, the F1 rating signifies that, even with excessive precision, the decrease recall is affecting total efficiency. This means that there’s room for enchancment in catching extra spam emails.
F1 rating vs. accuracy
- The dataset is imbalanced. That is frequent in fields like prognosis of obscure medical situations or spam detection, the place one class is comparatively uncommon.
- FN and FP are each necessary. For instance, medical screening checks search to steadiness catching precise points with not elevating false alarms.
- The mannequin must strike a steadiness between being too aggressive and too cautious. For instance, in spam filtering, a very cautious filter would possibly let by an excessive amount of spam (low recall) however hardly ever make errors (excessive precision). Then again, a very aggressive filter would possibly block actual emails (low precision) even when it does catch all spam (excessive recall).
Purposes of the F1 rating
Monetary fraud detection
Medical prognosis
Content material moderation
Moderating content material is a standard problem in on-line boards, social media platforms, and on-line marketplaces. To realize platform security with out overcensoring, these programs should steadiness precision and recall. The F1 rating can assist platforms decide how nicely their system balances these two elements.
Advantages of the F1 rating
Along with typically offering a extra nuanced view of mannequin efficiency than accuracy, the F1 rating offers a number of key benefits when evaluating classification mannequin efficiency. These advantages embody sooner mannequin coaching and optimization, lowered coaching prices, and catching overfitting early.
Quicker mannequin coaching and optimization
The F1 rating can assist velocity up mannequin coaching by offering a transparent reference metric that can be utilized to information optimization. As an alternative of tuning recall and precision individually, which typically entails complicated trade-offs, ML practitioners can concentrate on growing the F1 rating. With this streamlined method, optimum mannequin parameters might be recognized rapidly.
Diminished coaching prices
The F1 rating can assist ML practitioners make knowledgeable selections about when a mannequin is prepared for deployment by offering a nuanced, single measure of mannequin efficiency. With this data, practitioners can keep away from pointless coaching cycles, investments in computational assets, and having to amass or create extra coaching knowledge. Total, this may result in substantial value reductions when coaching classification fashions.
Catching overfitting early
Because the F1 rating considers each precision and recall, it might assist ML practitioners establish when a mannequin is turning into too specialised within the coaching knowledge. This downside, referred to as overfitting, is a standard situation with classification fashions. The F1 rating offers practitioners an early warning that they should regulate coaching earlier than the mannequin reaches a degree the place it’s unable to generalize on real-world knowledge.





