
How We Upgraded Our ML Infrastructure
At Grammarly, it’s essential that our numerous groups of researchers, linguists, and ML engineers have dependable entry to the computing assets they want each time they want them.
The tasks of each workforce are very totally different, and so are the infrastructure necessities wanted to perform their targets:
- Analytical and computational linguists: give attention to knowledge sampling, preprocessing and post-processing, knowledge annotation, and immediate engineering
- Researchers: work on mannequin coaching and analysis primarily based on knowledge and cutting-edge analysis papers
- ML engineers: deploy production-ready fashions into inference providers, making use of optimization methods to search out the perfect performance-versus-cost stability
Our legacy system was serving all of these wants, nevertheless it began struggling to maintain up with the rising demand. This motivated us to begin a mission to reinvent our ML infrastructure at Grammarly. On this article, we’ll describe our path and the challenges we confronted alongside the best way.
Legacy system design and limitations
Our legacy ML infrastructure system had a easy design, and it served us properly for almost seven years.
The system comprised a easy internet UI that offered an interactive interface for creating EC2 situations of a sure sort and operating predefined bash scripts to put in the required software program, relying on the use case. Then, all of the required setup was carried out in a background course of that utilized a dynamically created Terraform state to create a ready-to-use EC2 occasion.
As with every homegrown resolution, it’s widespread to come across distinctive bugs and sudden behaviors that may be tough to foretell. For instance, there was a time when the dynamic Terraform provisioning resulted in situations being provisioned twice. This created a problem, as these duplicated situations weren’t tracked, used, or deallocated. This prompted a big waste of cash till we found and resolved the problem.
Scalability was one other key problem we confronted. When customers wanted extra assets, our solely possibility for scaling vertically was to supply bigger situations. With the thrilling LLM revolution, this problem turned much more urgent, as securing massive situations in AWS might now take weeks! Furthermore, since every EC2 occasion was tied to the one that created it, this made assets much more scarce.
Apart from scalability points, there have been different drawbacks:
- Help points: These long-running, customized, stateful EC2 situations have been onerous to assist correctly and had lower than 25% utilization on common.
- Technical limitations: As a consequence of implementation particulars, the situations have been restricted to a single AWS area and a restricted set of availability zones, which sophisticated growth and fast entry to newer EC2 occasion varieties.
- Safety considerations: Safety patching and aligning with the most recent necessities was a problem.
Given the challenges and scope of labor required to handle them within the legacy system, we concluded that the time was proper for extra radical adjustments.
Implementation of the brand new ML infrastructure
As soon as we determined to construct a completely new infrastructure, we sat all the way down to listing the system’s primary necessities. At its core, there are simply three predominant components: storage, compute assets, and entry to different providers.
Compute assets: One key change was shifting from stateful, customized EC2 situations to dynamically allotted compute clusters on prime of shared computing assets. We achieved this by shifting from EC2 to EKS (Kubernetes setting), which allowed us to decouple storage from compute assets and transfer from customized to dynamically allotted assets.
Storage: Whereas EFS remained the principle storage possibility in legacy techniques, we moved from world shared storage to per-team EFS storage and offered S3 buckets as a extra appropriate possibility for sure use circumstances.
Entry to different providers: As an alternative of managing dozens of personal hyperlinks between totally different accounts, we centralized endpoint entry underneath ICAP Proxy via which each and every request was routed.
One of many mission’s core rules was to write down as little code as attainable and mix solely open-source options right into a working system.
In the long run, our technical selections could be summarized like this:
- Kubernetes (K8s)—the core trade commonplace for compute abstraction
- Karpenter—a regular for dynamic provisioning of compute assets in K8s
- KubeRay—cluster compute orchestration framework
- Argo CD—K8s GitOps and CI/CD software
- Python CLI / Service—a skinny wrapper to permit customers to work together with the system and handle their compute clusters
Let’s stroll via how we used these instruments.
How this all performs collectively
We use open-source applied sciences (K8s, Karpenter, Argo CD, KubeRay) for all deployments and orchestration. To make the system simply accessible to customers, we use solely easy customized shopper and server components.
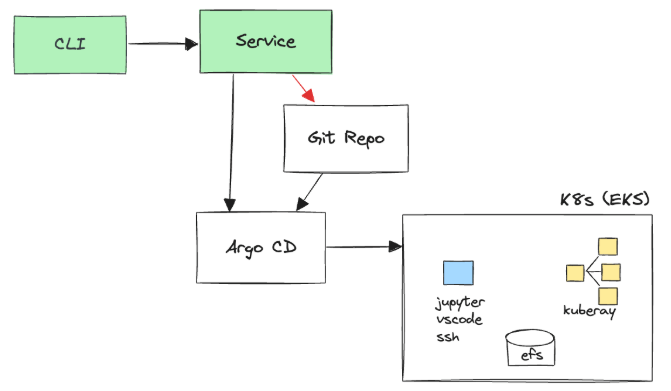
On person request, we have now a service that commits Helm values to our Git repo and polls the Argo CD API to get the deployment’s standing. Argo CD watches the configurations and automates the deployment to Kubernetes. Helm charts being deployed contain KubeRay (which gives cluster computing functionality), JupyterLab, VS Code, and SSH servers (which give totally different sorts of UI for customers to work together with) as deployment choices, relying on the use case.
This stream allowed us to dump complicated operations like provisioning and standing monitoring to open-source instruments, so we don’t want any customized code for these features.
Customers workflow
With the brand new infrastructure, our customers’ workflows have modified, nevertheless it additionally allowed to make them extra environment friendly.
Now, customers create a cluster that generates a YAML file template with all of the assets it must allocate, which Docker photographs must be used, and what sort of UI it ought to present.
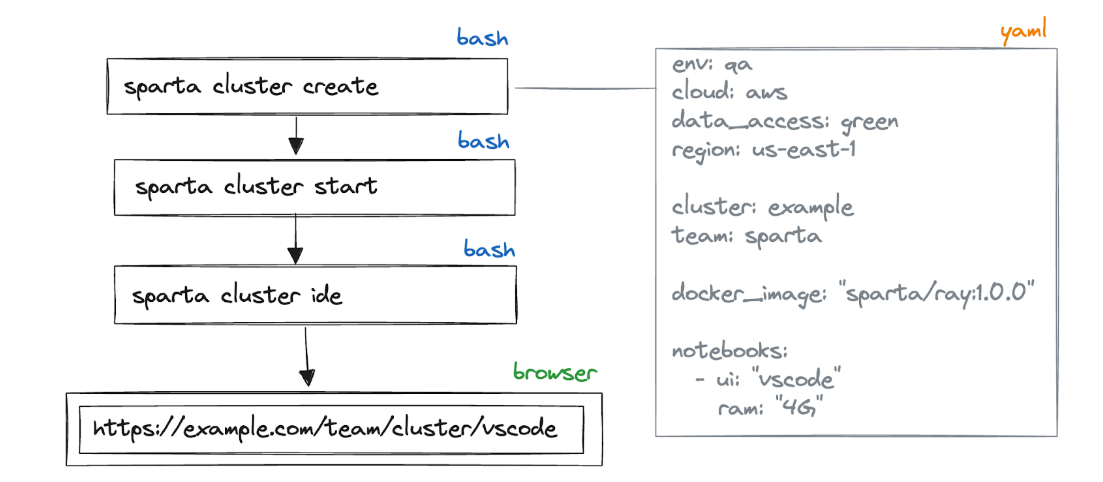
Afterward, they begin the cluster, which opens an internet UI within the browser or gives an SSH connection string.
Design and implementation challenges
Alongside the best way, we bumped into just a few fascinating design selections that we’d like to explain intimately.
The server commits to a distant Git repo
Within the new system, the CLI pushes cluster config to the back-end service. Nevertheless, the configuration ought to one way or the other be positioned within the centralized configuration Git repository, the place it may be found and deployed by Argo CD. Our design service instantly pushes adjustments to a distant Git repo (GitLab in our case). We name this a GitDb strategy, as we exchange the database with a Git repository and push adjustments to it.
As with every system that turns into common amongst customers, we have to scale it out by including new replicas. So now, a number of replicas of the service would possibly concurrently push commits to the identical distant Git department. Principally, we will get into hassle with a traditional distributed database write.
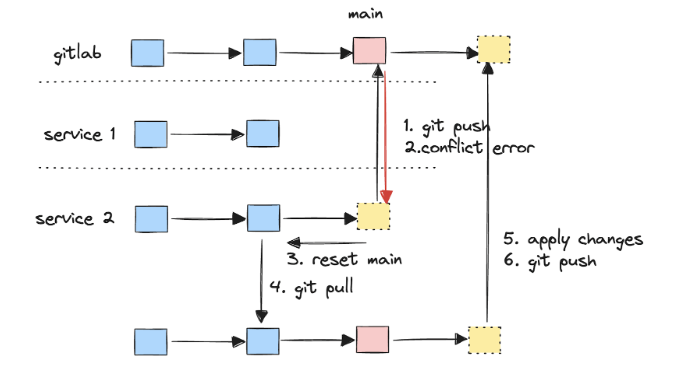
For instance, if one service reproduction makes an attempt to push to the GitLab predominant department whereas one other reproduction has already carried out so, a Git push battle error will happen. Due to this fact, you will need to implement well-tested revert-and-retry logic, just like the one within the image.
Ultimately, we would have liked to unravel more and more complicated concurrency issues associated to this design choice. We advise simplifying such customized options as a lot as attainable, resorting to extra complicated customized logic solely when essential.
A number of Karpenter provisioners
Karpenter was used to scale our clusters up and down robotically. Contemplating the varied wants of our workforce, we created specialised provisioners for every use case. It is usually essential to make sure that these provisioners don’t battle with each other, as conflicts might result in suboptimal scheduling selections.
There are three provisioners configured in our setup:
- The default provisioner serves CPU/RAM useful resource requests (i.e., non-GPU workloads).
- The GPU provisioner manages GPU assets, making certain non-GPU workloads usually are not scheduled on expensive GPU situations.
- The capability reservation provisioner manages massive assets and ensures smaller payloads received’t be scheduled for big situations.
Tight integration with capability reservations
One among our core use circumstances is coaching and fine-tuning LLMs (massive language fashions). We have now a quickly rising demand for big occasion varieties (like p4de.24xlarge, p5.48xlarge), which aren’t reliably accessible within the on-demand market. Due to this fact, we extensively use AWS Capability Reservations. We’ve constructed a complete integration round it to obviously visualize the present use of the reservations and supply notifications on expiring reservations.
Adoption challenges
The mission’s major problem was attaining person adoption. Motivation, function parity, and tight timelines have been the principle elements in adoption.
We approached this on a case-by-case foundation. We created an inventory of person tales to make sure that customers weren’t merely migrating to a brand new software but in addition gaining extra performance. This modified the context of the migration for the groups and helped prioritize. We additionally managed to obtain approval from senior administration to make the migration a company-wide aim.
One other important technical problem for adoption was utilizing Docker photographs and Kubernetes abstractions. Researchers are used to reveal, stateful EC2 situations, so we would have liked to doc and talk the variations in order that researchers felt snug once more. We developed templates and CI automation to simplify Docker picture creation, making it as simple as writing a customized bash script. Later, we additionally launched initialization bash scripts to supply a shorter suggestions loop and make the expertise much more just like the legacy system.
Advantages and impression
Whereas implementing the mission, we discovered it helpful to ensure we ourselves and all of the stakeholders understood the necessity for the mission and that customers noticed worth in migration to our new resolution.
Probably the most invaluable and measurable outcomes of the mission have been:
- Linguists profit from considerably decreasing setup time: We saved them a number of hours per individual per dash.
- ML workforce members wait a lot much less time for assets, as they will profit from utilizing a shared pool of huge occasion assets. Earlier than, they wanted to attend from just a few days to 30 days for computing assets. Now, it’s diminished to zero time, as we enabled the planning and sharing of useful resource wants prematurely.
- Our infrastructure turned simpler to patch and replace to align with new necessities, making safety stronger.
- Final however not least, we centralized our tooling round a single software throughout totally different groups, which enabled the sharing of assets and experience.
Closing ideas
This mission introduced us quite a few invaluable insights alongside the best way. If we have been to begin over, we’d positively give extra consideration to buyer wants and pains with the present tooling from the start. The mission was structured to be versatile and meet the customers’ future wants; nonetheless, a extra complete listing of necessities from the beginning would have helped us save appreciable effort in adjusting. We’d additionally keep away from repeating the identical errors made within the legacy system, resembling rising the complexity of the customized code base that helps the infrastructure. Moreover, we’d proactively search for ready-to-use options to interchange customized parts.
Our conclusion in the intervening time is that utterly changing our ML stack with a SaaS resolution wouldn’t exactly meet our wants and would scale back productiveness. Having full management and a deep understanding of the complete system places us in a robust place with our inside customers, who selected this resolution over different options. Moreover, having extendable and replaceable parts makes the setup extra versatile. That is in distinction to out-of-the-box all-in-one options like KubeFlow or Databricks. That mentioned, we always consider our tooling and modify to the trade; we’re open to revisiting this sooner or later.
If you wish to work on the frontier of ML and AI, and assist the world talk higher alongside the best way, try our job openings right here.





