
Recurrent Neural Community Fundamentals: What You Have to Know
Recurrent neural networks (RNNs) are important strategies within the realms of knowledge evaluation, machine studying (ML), and deep studying. This text goals to discover RNNs and element their performance, purposes, and benefits and drawbacks throughout the broader context of deep studying.
Desk of contents
RNNs vs. transformers and CNNs
What’s a recurrent neural community?
RNNs are one of many elementary deep studying fashions. They’ve completed very properly on pure language processing (NLP) duties, although transformers have supplanted them. Transformers are superior neural community architectures that enhance on RNN efficiency by, for instance, processing knowledge in parallel and with the ability to uncover relationships between phrases which might be far aside within the supply textual content (utilizing consideration mechanisms). Nonetheless, RNNs are nonetheless helpful for time-series knowledge and for conditions the place less complicated fashions are ample.
How RNNs work
To explain intimately how RNNs work, let’s return to the sooner instance job: Classify the sentiment of the sentence “He ate the pie fortunately.”
We begin with a skilled RNN that accepts textual content inputs and returns a binary output (1 representing constructive and 0 representing damaging). Earlier than the enter is given to the mannequin, the hidden state is generic—it was realized from the coaching course of however isn’t particular to the enter but.
The primary phrase, He, is handed into the mannequin. Contained in the RNN, its hidden state is then up to date (to hidden state h1) to include the phrase He. Subsequent, the phrase ate is handed into the RNN, and h1 is up to date (to h2) to incorporate this new phrase. This course of recurs till the final phrase is handed in. The hidden state (h4) is up to date to incorporate the final phrase. Then the up to date hidden state is used to generate both a 0 or 1.
Right here’s a visible illustration of how the RNN course of works:
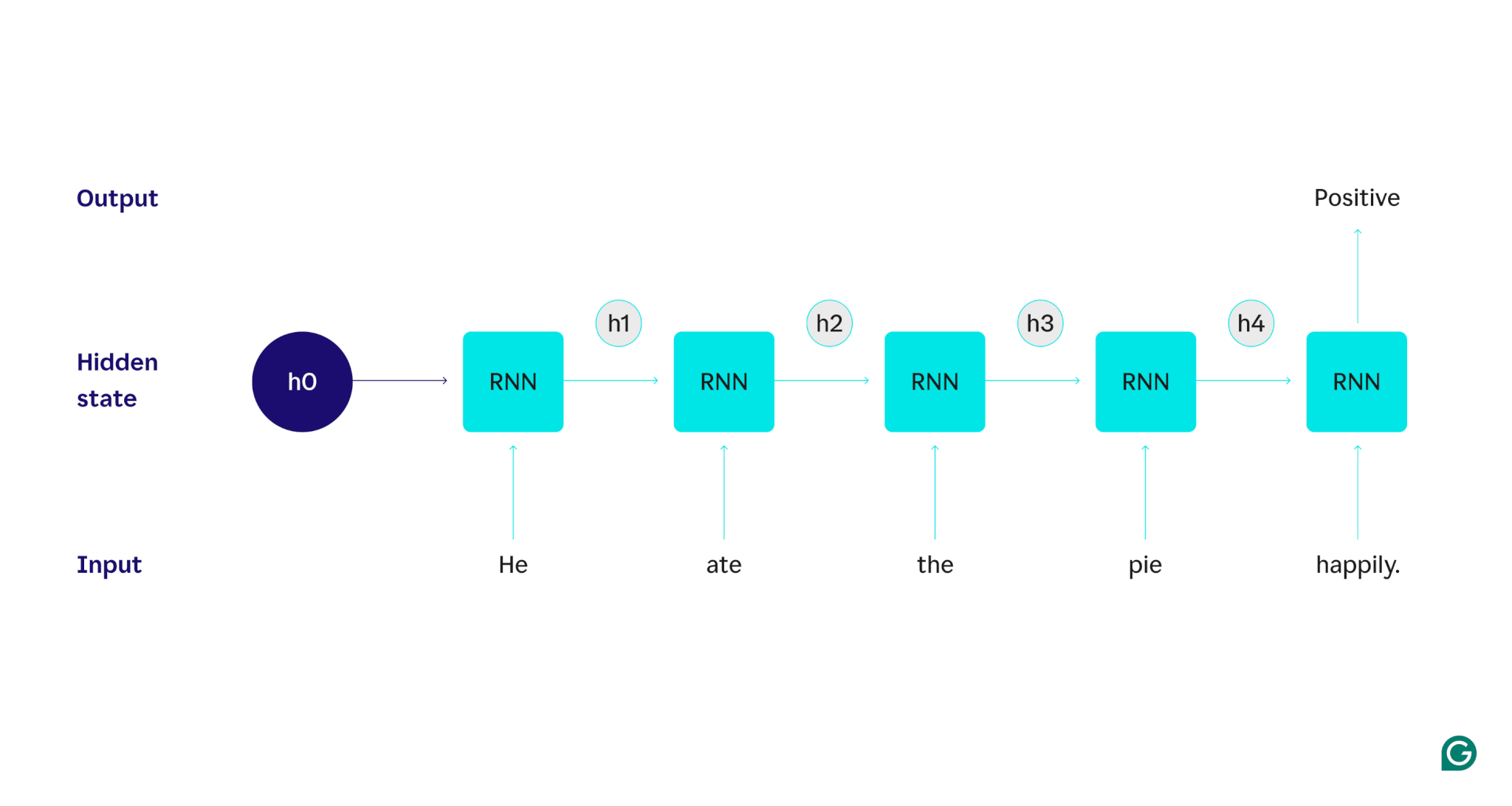
That recurrence is the core of the RNN, however there are a couple of different concerns:
- Textual content embedding: The RNN can’t course of textual content immediately since it really works solely on numeric representations. The textual content have to be transformed into embeddings earlier than it may be processed by an RNN.
- Output era: An output can be generated by the RNN at every step. Nonetheless, the output might not be very correct till a lot of the supply knowledge is processed. For instance, after processing solely the “He ate” a part of the sentence, the RNN is likely to be unsure as as to whether it represents a constructive or damaging sentiment—“He ate” may come throughout as impartial. Solely after processing the total sentence would the RNN’s output be correct.
- Coaching the RNN: The RNN have to be skilled to carry out sentiment evaluation precisely. Coaching entails utilizing many labeled examples (e.g., “He ate the pie angrily,” labeled as damaging), operating them by way of the RNN, and adjusting the mannequin based mostly on how far off its predictions are. This course of units the default worth and alter mechanism for the hidden state, permitting the RNN to be taught which phrases are vital for monitoring all through the enter.
Kinds of recurrent neural networks
There are a number of several types of RNNs, every various of their construction and utility. Primary RNNs differ principally within the dimension of their inputs and outputs. Superior RNNs, akin to lengthy short-term reminiscence (LSTM) networks, handle among the limitations of fundamental RNNs.
Primary RNNs
One-to-one RNN: This RNN takes in an enter of size one and returns an output of size one. Due to this fact, no recurrence truly occurs, making it an ordinary neural community fairly than an RNN. An instance of a one-to-one RNN could be a picture classifier, the place the enter is a single picture and the output is a label (e.g., “fowl”).
One-to-many RNN: This RNN takes in an enter of size one and returns a multipart output. For instance, in an image-captioning job, the enter is one picture, and the output is a sequence of phrases describing the picture (e.g., “A fowl crosses over a river on a sunny day”).
Many-to-one RNN: This RNN takes in a multipart enter (e.g., a sentence, a sequence of photographs, or time-series knowledge) and returns an output of size one. For instance, a sentence sentiment classifier (just like the one we mentioned), the place the enter is a sentence and the output is a single sentiment label (both constructive or damaging).
Many-to-many RNN: This RNN takes a multipart enter and returns a multipart output. An instance is a speech recognition mannequin, the place the enter is a sequence of audio waveforms and the output is a sequence of phrases representing the spoken content material.
Superior RNN: Lengthy short-term reminiscence (LSTM)
Lengthy short-term reminiscence networks are designed to deal with a major problem with commonplace RNNs: They neglect data over lengthy inputs. In commonplace RNNs, the hidden state is closely weighted towards current components of the enter. In an enter that’s 1000’s of phrases lengthy, the RNN will neglect vital particulars from the opening sentences. LSTMs have a particular structure to get round this forgetting downside. They’ve modules that choose and select which data to explicitly bear in mind and neglect. So current however ineffective data can be forgotten, whereas outdated however related data can be retained. Consequently, LSTMs are much more widespread than commonplace RNNs—they merely carry out higher on complicated or lengthy duties. Nonetheless, they don’t seem to be good since they nonetheless select to neglect gadgets.
RNNs vs. transformers and CNNs
Two different widespread deep studying fashions are convolutional neural networks (CNNs) and transformers. How do they differ?
RNNs vs. transformers
Each RNNs and transformers are closely utilized in NLP. Nonetheless, they differ considerably of their architectures and approaches to processing enter.
Structure and processing
- RNNs: RNNs course of enter sequentially, one phrase at a time, sustaining a hidden state that carries data from earlier phrases. This sequential nature signifies that RNNs can wrestle with long-term dependencies resulting from this forgetting, during which earlier data might be misplaced because the sequence progresses.
- Transformers: Transformers use a mechanism referred to as “consideration” to course of enter. Not like RNNs, transformers have a look at your entire sequence concurrently, evaluating every phrase with each different phrase. This method eliminates the forgetting problem, as every phrase has direct entry to your entire enter context. Transformers have proven superior efficiency in duties like textual content era and sentiment evaluation resulting from this functionality.
Parallelization
- RNNs: The sequential nature of RNNs signifies that the mannequin should full processing one a part of the enter earlier than transferring on to the following. That is very time-consuming, as every step is dependent upon the earlier one.
- Transformers: Transformers course of all components of the enter concurrently, as their structure doesn’t depend on a sequential hidden state. This makes them way more parallelizable and environment friendly. For instance, if processing a sentence takes 5 seconds per phrase, an RNN would take 25 seconds for a 5-word sentence, whereas a transformer would take solely 5 seconds.
Sensible implications
On account of these benefits, transformers are extra broadly utilized in business. Nonetheless, RNNs, significantly lengthy short-term reminiscence (LSTM) networks, can nonetheless be efficient for less complicated duties or when coping with shorter sequences. LSTMs are sometimes used as essential reminiscence storage modules in giant machine studying architectures.
RNNs vs. CNNs
CNNs are essentially completely different from RNNs when it comes to the information they deal with and their operational mechanisms.
Information sort
- RNNs: RNNs are designed for sequential knowledge, akin to textual content or time sequence, the place the order of the information factors is vital.
- CNNs: CNNs are used primarily for spatial knowledge, like photographs, the place the main target is on the relationships between adjoining knowledge factors (e.g., the colour, depth, and different properties of a pixel in a picture are carefully associated to the properties of different close by pixels).
Operation
- RNNs: RNNs keep a reminiscence of your entire sequence, making them appropriate for duties the place context and sequence matter.
- CNNs: CNNs function by native areas of the enter (e.g., neighboring pixels) by way of convolutional layers. This makes them extremely efficient for picture processing however much less so for sequential knowledge, the place long-term dependencies is likely to be extra vital.
Enter size
- RNNs: RNNs can deal with variable-length enter sequences with a much less outlined construction, making them versatile for various sequential knowledge sorts.
- CNNs: CNNs sometimes require fixed-size inputs, which generally is a limitation for dealing with variable-length sequences.
Functions of RNNs
RNNs are broadly utilized in numerous fields resulting from their capability to deal with sequential knowledge successfully.
Pure language processing
Language is a extremely sequential type of knowledge, so RNNs carry out properly on language duties. RNNs excel in duties akin to textual content era, sentiment evaluation, translation, and summarization. With libraries like PyTorch, somebody may create a easy chatbot utilizing an RNN and some gigabytes of textual content examples.
Speech recognition
Speech recognition is language at its core and so is very sequential, as properly. A many-to-many RNN may very well be used for this job. At every step, the RNN takes within the earlier hidden state and the waveform, outputting the phrase related to the waveform (based mostly on the context of the sentence as much as that time).
Music era
Music can be extremely sequential. The earlier beats in a music strongly affect the longer term beats. A many-to-many RNN may take a couple of beginning beats as enter after which generate extra beats as desired by the person. Alternatively, it may take a textual content enter like “melodic jazz” and output its greatest approximation of melodic jazz beats.
Benefits of RNNs
Good sequential efficiency
Smaller, less complicated fashions
RNNs normally have fewer mannequin parameters than transformers. The eye and feedforward layers in transformers require extra parameters to perform successfully. RNNs might be skilled with fewer runs and knowledge examples, making them extra environment friendly for less complicated use instances. This leads to smaller, inexpensive, and extra environment friendly fashions which might be nonetheless sufficiently performant.




