
What Is a Convolutional Neural Community?
Convolutional neural networks (CNNs) are basic instruments in knowledge evaluation and machine studying (ML). This information explains how CNNs work, how they differ from different neural networks, their functions, and the benefits and drawbacks related to their use.
Desk of contents
What’s a convolutional neural community?
A convolutional neural community (CNN) is a neural community integral to deep studying, designed to course of and analyze spatial knowledge. It employs convolutional layers with filters to robotically detect and be taught necessary options throughout the enter, making it significantly efficient for duties comparable to picture and video recognition.
Let’s unpack this definition a bit. Spatial knowledge is knowledge the place the components relate to one another by way of their place. Pictures are the perfect instance of this.
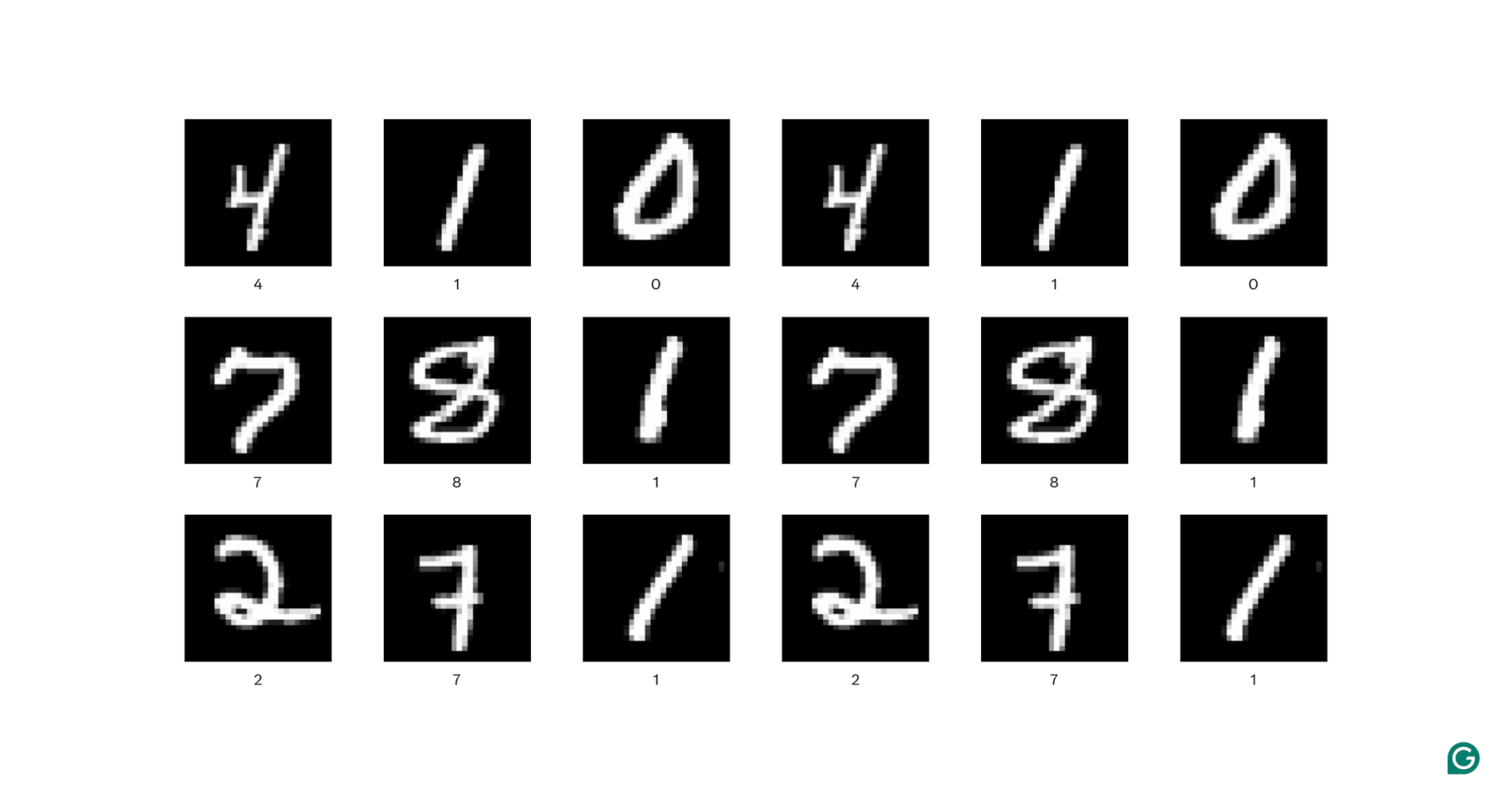
In every picture above, every white pixel is linked to every surrounding white pixel: They type the digit. The pixel places additionally inform a viewer the place the digit is positioned throughout the picture.

Options are attributes current throughout the picture. These attributes could be something from a barely tilted edge to the presence of a nostril or eye to a composition of eyes, mouths, and noses. Crucially, options could be composed of less complicated options (e.g., a watch consists of some curved edges and a central darkish spot).
Filters are the a part of the mannequin that detects these options throughout the picture. Every filter seems to be for one particular characteristic (e.g., an edge curving from left to proper) all through your complete picture.
Lastly, the “convolutional” in convolutional neural community refers to how a filter is utilized to a picture. We’ll clarify that within the subsequent part.
CNNs have proven robust efficiency on numerous picture duties, comparable to object detection and picture segmentation. A CNN mannequin (AlexNet) performed a major function within the rise of deep studying in 2012.
How CNNs work
Let’s discover the general structure of a CNN by utilizing the instance of figuring out which quantity (0–9) is in a picture.
Earlier than feeding the picture into the mannequin, the picture have to be become a numerical illustration (or encoding). For black-and-white photographs, every pixel is assigned a quantity: 255 if it’s utterly white and 0 if it’s utterly black (generally normalized to 1 and 0). For colour photographs, every pixel is assigned three numbers: one for a way a lot purple, inexperienced, and blue it accommodates, often known as its RGB worth. So a picture of 256×256 pixels (with 65,536 pixels) would have 65,536 values in its black-and-white encoding and 196,608 values in its colour encoding.
The mannequin then processes the picture by way of three kinds of layers:
1
Convolutional layer: This layer applies filters to its enter. Every filter is a grid of numbers of an outlined dimension (e.g., 3×3). This grid is overlaid on the picture ranging from the highest left; the pixel values from rows 1–3 in columns 1–3 might be used. These pixel values are multiplied by the values within the filter after which summed. This sum is then positioned within the filter output grid in row 1, column 1. Then the filter slides one pixel to the suitable and repeats the method till it has coated all rows and columns within the picture. By sliding one pixel at a time, the filter can discover options anyplace within the picture, a property often known as translational invariance. Every filter creates its personal output grid, which is then despatched to the subsequent layer.
2
Pooling layer: This layer summarizes the characteristic info from the convolution layer. The convolutional layer returns an output bigger than its enter (every filter returns a characteristic map roughly the identical dimension because the enter, and there are a number of filters). The pooling layer takes every characteristic map and applies one more grid to it. This grid takes both the common or the max of the values in it and outputs that. Nonetheless, this grid doesn’t transfer one pixel at a time; it’ll skip to the subsequent patch of pixels. For instance, a 3×3 pooling grid will first work on the pixels in rows 1–3 and columns 1–3. Then, it’ll keep in the identical row however transfer to columns 4–6. After protecting all of the columns within the first set of rows (1–3), it’ll transfer right down to rows 4–6 and deal with these columns. This successfully reduces the variety of rows and columns within the output. The pooling layer helps scale back complexity, makes the mannequin extra sturdy to noise and small adjustments, and helps the mannequin give attention to essentially the most important options.
3
Absolutely linked layer: After a number of rounds of convolutional and pooling layers, the ultimate characteristic maps are handed to a totally linked neural community layer, which returns the output we care about (e.g., the likelihood that the picture is a selected quantity). The characteristic maps have to be flattened (every row of a characteristic map is concatenated into one lengthy row) after which mixed (every lengthy characteristic map row is concatenated right into a mega row).
Here’s a visible illustration of the CNN structure, illustrating how every layer processes the enter picture and contributes to the ultimate output:

A number of further notes on the method:
- Every successive convolutional layer finds higher-level options. The primary convolutional layer detects edges, spots, or easy patterns. The subsequent convolutional layer takes the pooled output of the primary convolutional layer as its enter, enabling it to detect compositions of lower-lever options that type higher-level options, comparable to a nostril or eye.
- The mannequin requires coaching. Throughout coaching, a picture is handed by way of all of the layers (with random weights at first), and the output is generated. The distinction between the output and the precise reply is used to regulate the weights barely, making the mannequin extra prone to reply appropriately sooner or later. That is completed by gradient descent, the place the coaching algorithm calculates how a lot every mannequin weight contributes to the ultimate reply (utilizing partial derivatives) and strikes it barely within the course of the proper reply. The pooling layer doesn’t have any weights, so it’s unaffected by the coaching course of.
- CNNs can work solely on photographs of the identical dimension as those they have been skilled on. If a mannequin was skilled on photographs with 256×256 pixels, then any picture bigger will must be downsampled, and any smaller picture will must be upsampled.
CNNs vs. RNNs and transformers
Convolutional neural networks are sometimes talked about alongside recurrent neural networks (RNNs) and transformers. So how do they differ?
CNNs vs. RNNs
RNNs and CNNs function in several domains. RNNs are greatest fitted to sequential knowledge, comparable to textual content, whereas CNNs excel with spatial knowledge, comparable to photographs. RNNs have a reminiscence module that retains observe of beforehand seen components of an enter to contextualize the subsequent half. In distinction, CNNs contextualize components of the enter by its rapid neighbors. As a result of CNNs lack a reminiscence module, they don’t seem to be well-suited for textual content duties: They might overlook the primary phrase in a sentence by the point they attain the final phrase.
CNNs vs. transformers
Transformers are additionally closely used for sequential duties. They will use any a part of the enter to contextualize new enter, making them well-liked for pure language processing (NLP) duties. Nonetheless, transformers have additionally been utilized to pictures not too long ago, within the type of imaginative and prescient transformers. These fashions soak up a picture, break it into patches, run consideration (the core mechanism in transformer architectures) over the patches, after which classify the picture. Imaginative and prescient transformers can outperform CNNs on giant datasets, however they lack the translational invariance inherent to CNNs. Translational invariance in CNNs permits the mannequin to acknowledge objects no matter their place within the picture, making CNNs extremely efficient for duties the place the spatial relationship of options is necessary.
Functions of CNNs
Picture classification
Speech recognition
Picture segmentation
Picture segmentation includes figuring out and drawing boundaries round completely different objects in a picture. CNNs are well-liked for this job as a result of their robust efficiency in recognizing numerous objects. As soon as a picture is segmented, we are able to higher perceive its content material. For instance, one other deep studying mannequin may analyze the segments and describe this scene: “Two persons are strolling in a park. There’s a lamppost to their proper and a automobile in entrance of them.” Within the medical area, picture segmentation can differentiate tumors from regular cells in scans. For autonomous autos, it might establish lane markings, street indicators, and different autos.
Benefits of CNNs
CNNs are extensively used within the trade for a number of causes.
Robust picture efficiency
No handbook characteristic engineering
Earlier than CNNs, the best-performing picture fashions required important handbook effort. Area consultants needed to create modules to detect particular kinds of options (e.g., filters for edges), a time-consuming course of that lacked flexibility for numerous photographs. Every set of photographs wanted its personal characteristic set. In distinction, the primary well-known CNN (AlexNet) may categorize 20,000 kinds of photographs robotically, lowering the necessity for handbook characteristic engineering.
Disadvantages of CNNs
After all, there are tradeoffs to utilizing CNNs.

