
What Is a Resolution Tree in Machine Studying?
Resolution timber are one of the crucial widespread instruments in a knowledge analyst’s machine studying toolkit. On this information, you’ll be taught what determination timber are, how they’re constructed, numerous functions, advantages, and extra.
Desk of contents
What’s a choice tree?
In machine studying (ML), a choice tree is a supervised studying algorithm that resembles a flowchart or determination chart. In contrast to many different supervised studying algorithms, determination timber can be utilized for each classification and regression duties. Knowledge scientists and analysts usually use determination timber when exploring new datasets as a result of they’re straightforward to assemble and interpret. Moreover, determination timber can assist determine vital information options that could be helpful when making use of extra complicated ML algorithms.
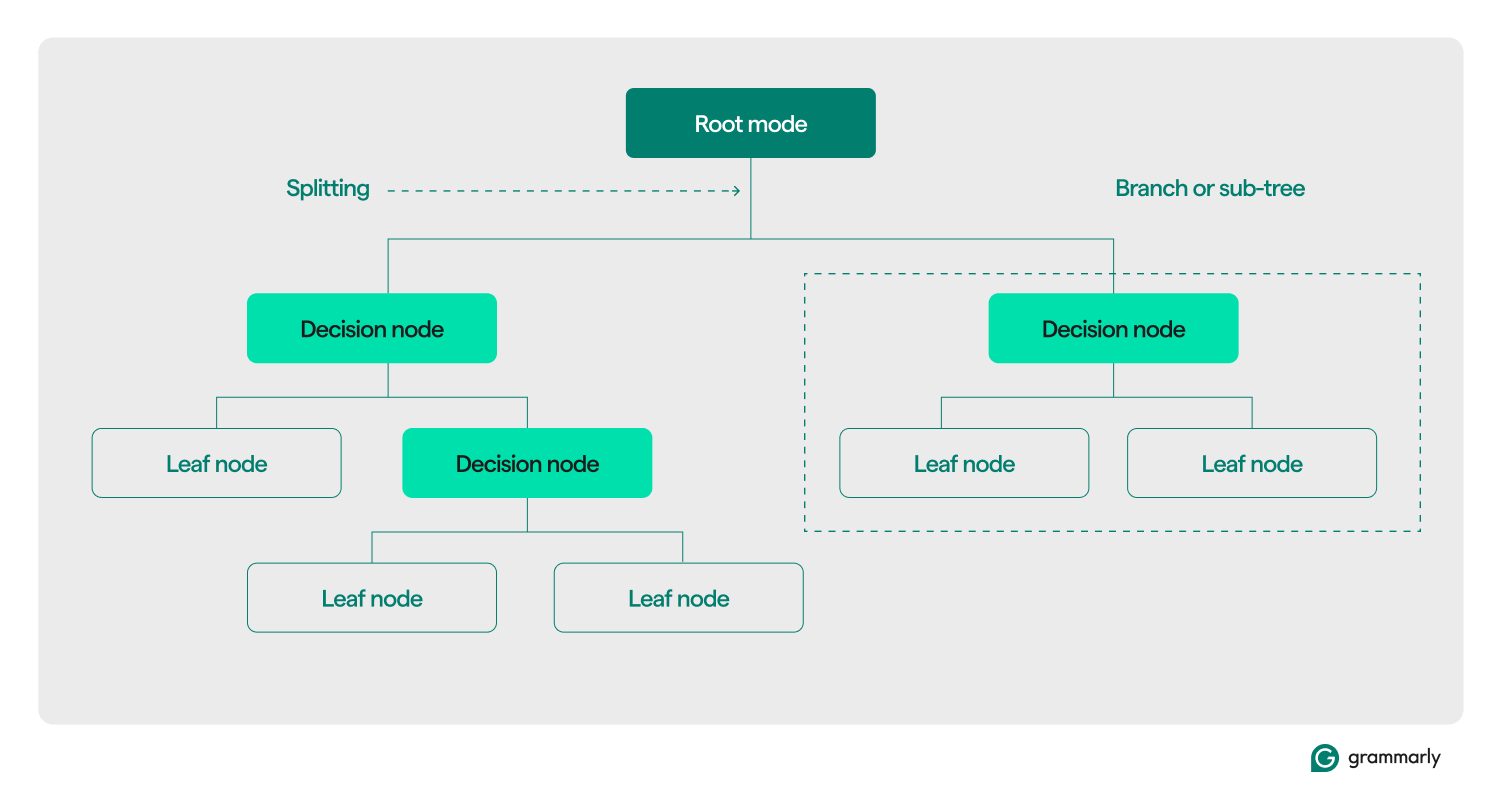
Resolution tree terminology
Structurally, a choice tree sometimes consists of three parts: a root node, leaf nodes, and determination (or inner) nodes. Identical to flowcharts or timber in different domains, selections in a tree often transfer in a single path (both down or up), ranging from the basis node, passing by means of some determination nodes, and ending at a particular leaf node. Every leaf node connects a subset of the coaching information to a label. The tree is assembled by means of an ML coaching and optimization course of, and as soon as constructed, it may be utilized to numerous datasets.
Right here’s a deeper dive into the remainder of the terminology:
- Root node: A node holding the primary of a collection of questions that the choice tree will ask in regards to the information. The node will probably be linked to not less than one (however often two or extra) determination or leaf nodes.
- Resolution nodes (or inner nodes): Further nodes containing questions. A choice node will comprise precisely one query in regards to the information and direct the dataflow to one in all its youngsters primarily based on the response.
- Kids: A number of nodes {that a} root or determination node factors to. They signify an inventory of subsequent choices that the decision-making course of can take because it analyzes information.
- Leaf nodes (or terminal nodes): Nodes that point out the choice course of has been accomplished. As soon as the choice course of reaches a leaf node, it’ll return the worth(s) from the leaf node as its output.
- Label (class, class): Typically, a string related by a leaf node with a number of the coaching information. For instance, a leaf may affiliate the label “Glad buyer” with a set of particular clients that the choice tree ML coaching algorithm was offered with.
- Department (or sub-tree): That is the set of nodes consisting of a choice node at any level within the tree, along with all of its youngsters and their youngsters, all the best way right down to the leaf nodes.
- Pruning: An optimization operation sometimes carried out on the tree to make it smaller and assist it return outputs quicker. Pruning often refers to “post-pruning,” which entails algorithmically eradicating nodes or branches after the ML coaching course of has constructed the tree. “Pre-pruning” refers to setting an arbitrary restrict on how deep or massive a choice tree can develop throughout coaching. Each processes implement a most complexity for the choice tree, often measured by its most depth or top. Much less widespread optimizations embrace limiting the utmost variety of determination nodes or leaf nodes.
- Splitting: The core transformation step carried out on a choice tree throughout coaching. It entails dividing a root or determination node into two or extra sub-nodes.
- Classification: An ML algorithm that makes an attempt to determine which (out of a relentless and discrete checklist of courses, classes, or labels) is the almost certainly one to use to a bit of information. It would try to reply questions like “Which day of the week is greatest for reserving a flight?” Extra on classification under.
- Regression: An ML algorithm that makes an attempt to foretell a steady worth, which can not all the time have bounds. It would try to reply (or predict the reply) to questions like “How many individuals are prone to e book a flight subsequent Tuesday?” We’ll speak extra about regression timber within the subsequent part.
Varieties of determination timber
Resolution timber are sometimes grouped into two classes: classification timber and regression timber. A particular tree could also be constructed to use to classification, regression, or each use circumstances. Most trendy determination timber use the CART (Classification and Regression Bushes) algorithm, which may carry out each kinds of duties.
Classification timber
Classification timber, the commonest kind of determination tree, try to resolve a classification drawback. From an inventory of doable solutions to a query (usually so simple as “sure” or “no”), a classification tree will select the almost certainly one after asking some questions in regards to the information it’s offered with. They’re often carried out as binary timber, which means every determination node has precisely two youngsters.
Classification timber may attempt to reply multiple-choice questions equivalent to “Is that this buyer happy?” or “Which bodily retailer is prone to be visited by this shopper?” or “Will tomorrow be day to go to the golf course?”
The 2 most typical strategies to measure the standard of a classification tree are primarily based on data achieve and entropy:
- Info achieve: The effectivity of a tree is enhanced when it asks fewer questions earlier than reaching a solution. Info achieve measures how “rapidly” a tree can obtain a solution by evaluating how rather more data is realized a couple of piece of information at every determination node. It assesses whether or not a very powerful and helpful questions are requested first within the tree.
- Entropy: Accuracy is essential for determination tree labels. Entropy metrics measure this accuracy by evaluating the labels produced by the tree. They assess how usually a random piece of information finally ends up with the mistaken label and the similarity amongst all items of coaching information that obtain the identical label.
Extra superior measurements of tree high quality embrace the gini index, achieve ratio, chi-square evaluations, and numerous measurements for variance discount.
Regression timber
Regression timber are sometimes utilized in regression evaluation for superior statistical evaluation or to foretell information from a steady, probably unbounded vary. Given a spread of steady choices (e.g., zero to infinity on the true quantity scale), the regression tree makes an attempt to foretell the almost certainly match for a given piece of information after asking a collection of questions. Every query narrows down the potential vary of solutions. As an example, a regression tree could be used to foretell credit score scores, income from a line of enterprise, or the variety of interactions on a advertising and marketing video.
The accuracy of regression timber is often evaluated utilizing metrics equivalent to imply sq. error or imply absolute error, which calculate how far off a particular set of predictions is in comparison with the precise values.
How determination timber work
For example of supervised studying, determination timber depend on well-formatted information for coaching. The supply information often comprises an inventory of values that the mannequin ought to be taught to foretell or classify. Every worth ought to have an connected label and an inventory of related options—properties the mannequin ought to be taught to affiliate with the label.
Constructing or coaching
Throughout the coaching course of, determination nodes within the determination tree are recursively break up into extra particular nodes based on a number of coaching algorithms. A human-level description of the method may appear like this:
- Begin with the basis node linked to all the coaching set.
- Cut up the basis node: Utilizing a statistical strategy, assign a choice to the basis node primarily based on one of many information options and distribute the coaching information to not less than two separate leaf nodes, linked as youngsters to the basis.
- Recursively apply step two to every of the kids, turning them from leaf nodes into determination nodes. Cease when some restrict is reached (e.g., the peak/depth of the tree, a measure of the standard of kids in every leaf at every node, and so on.) or when you’ve run out of information (i.e., every leaf comprises information factors which might be associated to precisely one label).
The choice of which options to think about at every node differs for classification, regression, and mixed classification and regression use circumstances. There are various algorithms to select from for every situation. Typical algorithms embrace:
- ID3 (classification): Optimizes entropy and data achieve
- C4.5 (classification): A extra complicated model of ID3, including normalization to data achieve
- CART (classification/regression): “Classification and regression tree”; a grasping algorithm that optimizes for minimal impurity in consequence units
- CHAID (classification/regression): “Chi-square computerized interplay detection”; makes use of chi-squared measurements as an alternative of entropy and data achieve
- MARS (classification/regression): Makes use of piecewise linear approximations to seize non-linearities
A typical coaching regime is the random forest. A random forest, or a random determination forest, is a system that builds many associated determination timber. A number of variations of a tree could be educated in parallel utilizing combos of coaching algorithms. Based mostly on numerous measurements of tree high quality, a subset of those timber will probably be used to provide a solution. For classification use circumstances, the category chosen by the biggest variety of timber is returned as the reply. For regression use circumstances, the reply is aggregated, often because the imply or common prediction of particular person timber.
Evaluating and utilizing determination timber
As soon as a choice tree has been constructed, it will probably classify new information or predict values for a particular use case. It’s vital to maintain metrics on tree efficiency and use them to guage accuracy and error frequency. If the mannequin deviates too removed from anticipated efficiency, it could be time to retrain it on new information or discover different ML methods to use to that use case.
Purposes of determination timber in ML
Resolution timber have a variety of functions in numerous fields. Listed here are some examples for example their versatility:
Knowledgeable private decision-making
A person may hold observe of information about, say, the eating places they’ve been visiting. They could observe any related particulars—equivalent to journey time, wait time, delicacies supplied, opening hours, common overview rating, price, and most up-to-date go to, coupled with a satisfaction rating for the person’s go to to that restaurant. A choice tree could be educated on this information to foretell the possible satisfaction rating for a brand new restaurant.
Calculate possibilities round buyer conduct
Buyer help methods may use determination timber to foretell or classify buyer satisfaction. A choice tree could be educated to foretell buyer satisfaction primarily based on numerous elements, equivalent to whether or not the shopper contacted help or made a repeat buy or primarily based on actions carried out inside an app. Moreover, it will probably incorporate outcomes from satisfaction surveys or different buyer suggestions.
Assist inform enterprise selections
For sure enterprise selections with a wealth of historic information, a choice tree can present estimates or predictions for the subsequent steps. For instance, a enterprise that collects demographic and geographic details about its clients can practice a choice tree to guage which new geographic places are prone to be worthwhile or needs to be prevented. Resolution timber may also assist decide the perfect classification boundaries for current demographic information, equivalent to figuring out age ranges to think about individually when grouping clients.
Characteristic choice for superior ML and different use circumstances
Resolution tree buildings are human readable and comprehensible. As soon as a tree is constructed, it’s doable to determine which options are most related to the dataset and in what order. This data can information the event of extra complicated ML methods or determination algorithms. As an example, if a enterprise learns from a choice tree that clients prioritize the price of a product above all else, it will probably focus extra complicated ML methods on this perception or ignore price when exploring extra nuanced options.
Benefits of determination timber in ML
Resolution timber supply a number of important benefits that make them a well-liked alternative in ML functions. Listed here are some key advantages:
Fast and straightforward to construct
Resolution timber are one of the crucial mature and well-understood ML algorithms. They don’t rely upon notably complicated calculations, and they are often constructed rapidly and simply. So long as the knowledge required is available, a choice tree is a simple first step to take when contemplating ML options to an issue.
Simple for people to know
The output from determination timber is especially straightforward to learn and interpret. The graphical illustration of a choice tree doesn’t rely upon a sophisticated understanding of statistics. As such, determination timber and their representations can be utilized to interpret, clarify, and help the outcomes of extra complicated analyses. Resolution timber are glorious at discovering and highlighting a number of the high-level properties of a given dataset.
Minimal information processing required
Resolution timber could be constructed simply as simply on incomplete information or information with outliers included. Given information embellished with attention-grabbing options, the choice tree algorithms have a tendency to not be affected as a lot as different ML algorithms if they’re fed information that hasn’t been preprocessed.
Disadvantages of determination timber in ML
Whereas determination timber supply many advantages, additionally they include a number of drawbacks:
Vulnerable to overfitting
Resolution timber are susceptible to overfitting, which happens when a mannequin learns the noise and particulars within the coaching information, lowering its efficiency on new information. For instance, if the coaching information is incomplete or sparse, small modifications within the information can produce considerably completely different tree buildings. Superior methods like pruning or setting a most depth can enhance tree conduct. In follow, determination timber usually want updating with new data, which may considerably alter their construction.
Poor scalability
Along with their tendency to overfit, determination timber wrestle with extra superior issues that require considerably extra information. In comparison with different algorithms, the coaching time for determination timber will increase quickly as information volumes develop. For bigger datasets which may have important high-level properties to detect, determination timber usually are not a terrific match.
Not as efficient for regression or steady use circumstances
Resolution timber don’t be taught complicated information distributions very properly. They break up the characteristic area alongside traces which might be straightforward to know however mathematically easy. For complicated issues the place outliers are related, regression, and steady use circumstances, this usually interprets into a lot poorer efficiency than different ML fashions and methods.




