
What Is an Autoencoder? A Newbie’s Information
Autoencoders are an integral part of deep studying, significantly in unsupervised machine studying duties. On this article, we’ll discover how autoencoders operate, their structure, and the varied varieties obtainable. You’ll additionally uncover their real-world functions, together with the benefits and trade-offs concerned in utilizing them.
Desk of contents
What’s an autoencoder?
Autoencoders are a kind of neural community utilized in deep studying to study environment friendly, lower-dimensional representations of enter information, that are then used to reconstruct the unique information. By doing so, this community learns probably the most important options of the information throughout coaching with out requiring specific labels, making it a part of self-supervised studying. Autoencoders are extensively utilized in duties similar to picture denoising, anomaly detection, and information compression, the place their means to compress and reconstruct information is effective.
Autoencoder structure
An autoencoder consists of three components: an encoder, a bottleneck (also referred to as the latent area or code), and a decoder. These parts work collectively to seize the important thing options of the enter information and use them to generate correct reconstructions.
Autoencoders optimize their output by adjusting the weights of each the encoder and decoder, aiming to supply a compressed illustration of the enter that preserves essential options. This optimization minimizes reconstruction error, which represents the distinction between the enter and the output information.
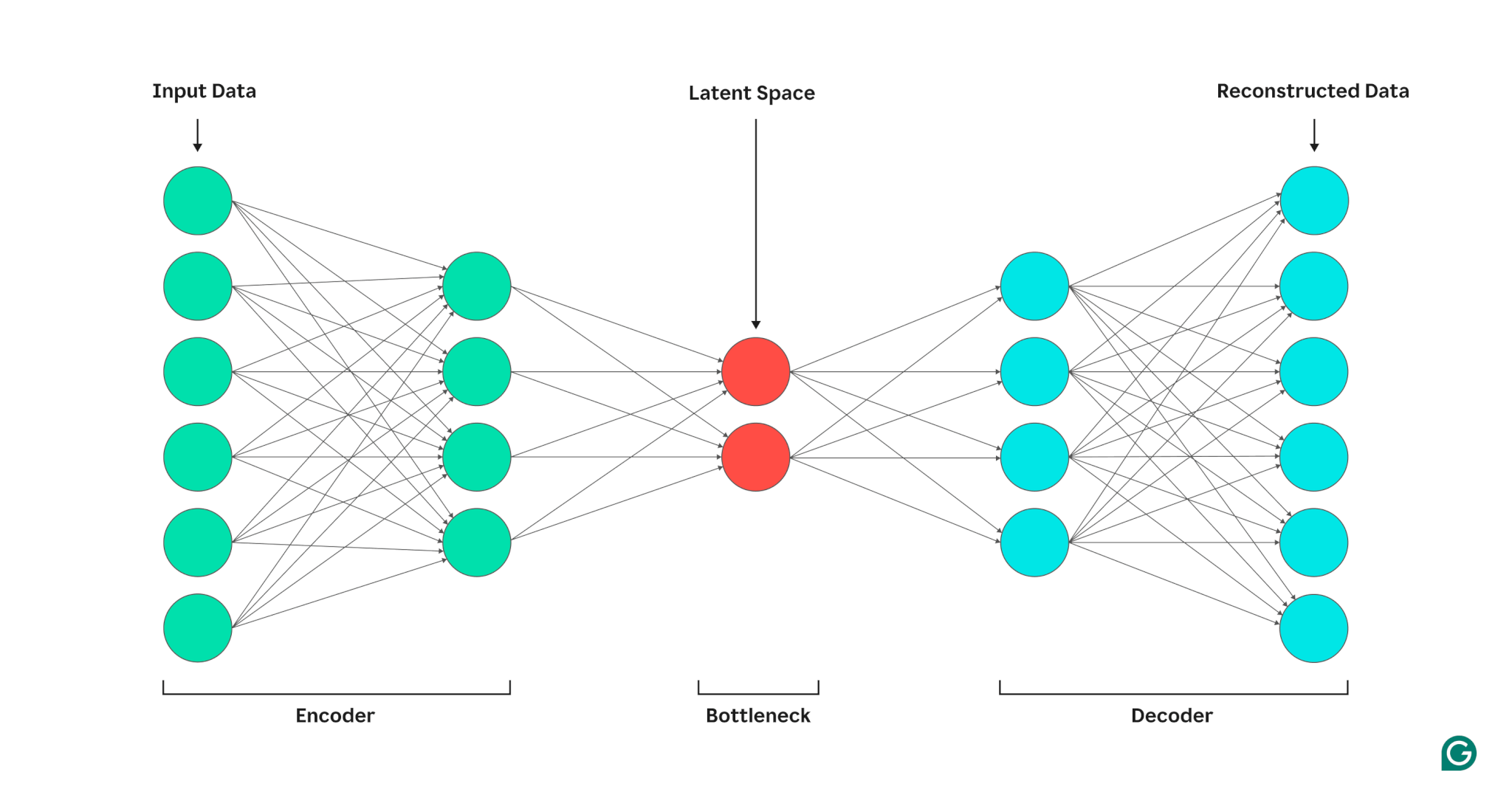
Encoder
First, the encoder compresses the enter information right into a extra environment friendly illustration. Encoders usually encompass a number of layers with fewer nodes in every layer. As the information is processed by means of every layer, the lowered variety of nodes forces the community to study crucial options of the information to create a illustration that may be saved in every layer. This course of, often called dimensionality discount, transforms the enter right into a compact abstract of the important thing traits of the information. Key hyperparameters within the encoder embrace the variety of layers and neurons per layer, which decide the depth and granularity of the compression, and the activation operate, which dictates how information options are represented and reworked at every layer.
Bottleneck
The bottleneck, also referred to as the latent area or code, is the place the compressed illustration of the enter information is saved throughout processing. The bottleneck has a small variety of nodes; this limits the quantity of knowledge that may be saved and determines the extent of compression. The variety of nodes within the bottleneck is a tunable hyperparameter, permitting customers to manage the trade-off between compression and information retention. If the bottleneck is just too small, the autoencoder could reconstruct the information incorrectly because of the lack of essential particulars. Alternatively, if the bottleneck is just too massive, the autoencoder could merely copy the enter information as a substitute of studying a significant, common illustration.
Decoder
On this last step, the decoder re-creates the unique information from the compressed type utilizing the important thing options discovered in the course of the encoding course of. The standard of this decompression is quantified utilizing the reconstruction error, which is actually a measure of how totally different the reconstructed information is from the enter. Reconstruction error is mostly calculated utilizing imply squared error (MSE). As a result of MSE measures the squared distinction between the unique and reconstructed information, it gives a mathematically simple solution to penalize bigger reconstruction errors extra closely.
Forms of autoencoders
Denoising autoencoders
Sparse autoencoders
Variational autoencoders (VAEs)
Contractive autoencoders
Contractive autoencoders introduce a further penalty time period in the course of the calculation of reconstruction error, encouraging the mannequin to study characteristic representations which are strong to noise. This penalty helps stop overfitting by selling characteristic studying that’s invariant to small variations in enter information. In consequence, contractive autoencoders are extra strong to noise than commonplace autoencoders.
Convolutional autoencoders (CAEs)
CAEs make the most of convolutional layers to seize spatial hierarchies and patterns inside high-dimensional information. Using convolutional layers makes CAEs significantly properly fitted to processing picture information. CAEs are generally utilized in duties like picture compression and anomaly detection in pictures.
Purposes of autoencoders in AI
Dimensionality discount
Anomaly detection
Denoising
Denoising autoencoders can clear noisy information by studying to reconstruct it from noisy coaching inputs. This functionality makes denoising autoencoders beneficial for duties like picture optimization, together with enhancing the standard of blurry images. Denoising autoencoders are additionally helpful in sign processing, the place they will clear noisy indicators for extra environment friendly processing and evaluation.
Benefits of autoencoders
Capable of study from unlabeled information
Automated characteristic studying
Nonlinear characteristic extraction
Autoencoders can deal with nonlinear relationships in enter information, permitting the mannequin to seize key options from extra advanced information representations. This means signifies that autoencoders have a bonus over fashions that may work solely with linear information, as they will deal with extra advanced datasets.


