
What Is Overfitting in Machine Studying?
Overfitting is a standard downside that comes up when coaching machine studying( ML) fashions. It could actually negatively impression a mannequin’s means to generalize past the coaching knowledge, resulting in inaccurate predictions in real-world eventualities. On this article, we’ll discover what overfitting is, the way it happens, the frequent causes behind it, and efficient methods to detect and forestall it.
Desk of contents
What’s overfitting?
Overfitting is when a machine studying mannequin learns the underlying patterns and the noise within the coaching knowledge, changing into overly specialised in that particular dataset. This extreme concentrate on the main points of the coaching knowledge ends in poor efficiency when the mannequin is utilized to new, unseen knowledge, because it fails to generalize past the information it was skilled on.
How does overfitting occur?
Overfitting happens when a mannequin learns an excessive amount of from the precise particulars and noise within the coaching knowledge, making it overly delicate to patterns that aren’t significant to generalization. For instance, think about a mannequin constructed to foretell worker efficiency based mostly on historic evaluations. If the mannequin overfits, it would focus an excessive amount of on particular, non-generalizable particulars, such because the distinctive ranking model of a former supervisor or explicit circumstances throughout a previous overview cycle. Moderately than studying the broader, significant elements that contribute to efficiency—like abilities, expertise, or mission outcomes—the mannequin could wrestle to use its data to new staff or evolve analysis standards. This results in much less correct predictions when the mannequin is utilized to knowledge that differs from the coaching set.
Overfitting vs. underfitting

3
Overfitting: Within the closing instance, the mannequin makes use of a extremely complicated, wavy curve to suit the coaching knowledge. Whereas this curve may be very correct for the coaching knowledge, it additionally captures random noise and outliers that don’t signify the precise relationship. This mannequin is overfitting as a result of it’s so finely tuned to the coaching knowledge that it’s prone to make poor predictions on new, unseen knowledge.
Widespread causes of overfitting
- Inadequate coaching knowledge
- Inaccurate, misguided, or irrelevant knowledge
- Massive weights
- Overtraining
- Mannequin structure is simply too subtle
Inadequate coaching knowledge
Inaccurate, misguided, or irrelevant knowledge
Massive weights
Overtraining
Mannequin structure is simply too complicated
Extra complicated architectures can seize detailed patterns within the coaching knowledge. Nonetheless, this complexity will increase the probability of overfitting, because the mannequin may be taught to seize noise or irrelevant particulars that don’t contribute to correct predictions on new knowledge. Simplifying the structure or utilizing regularization strategies might help cut back the danger of overfitting.
The best way to detect overfitting
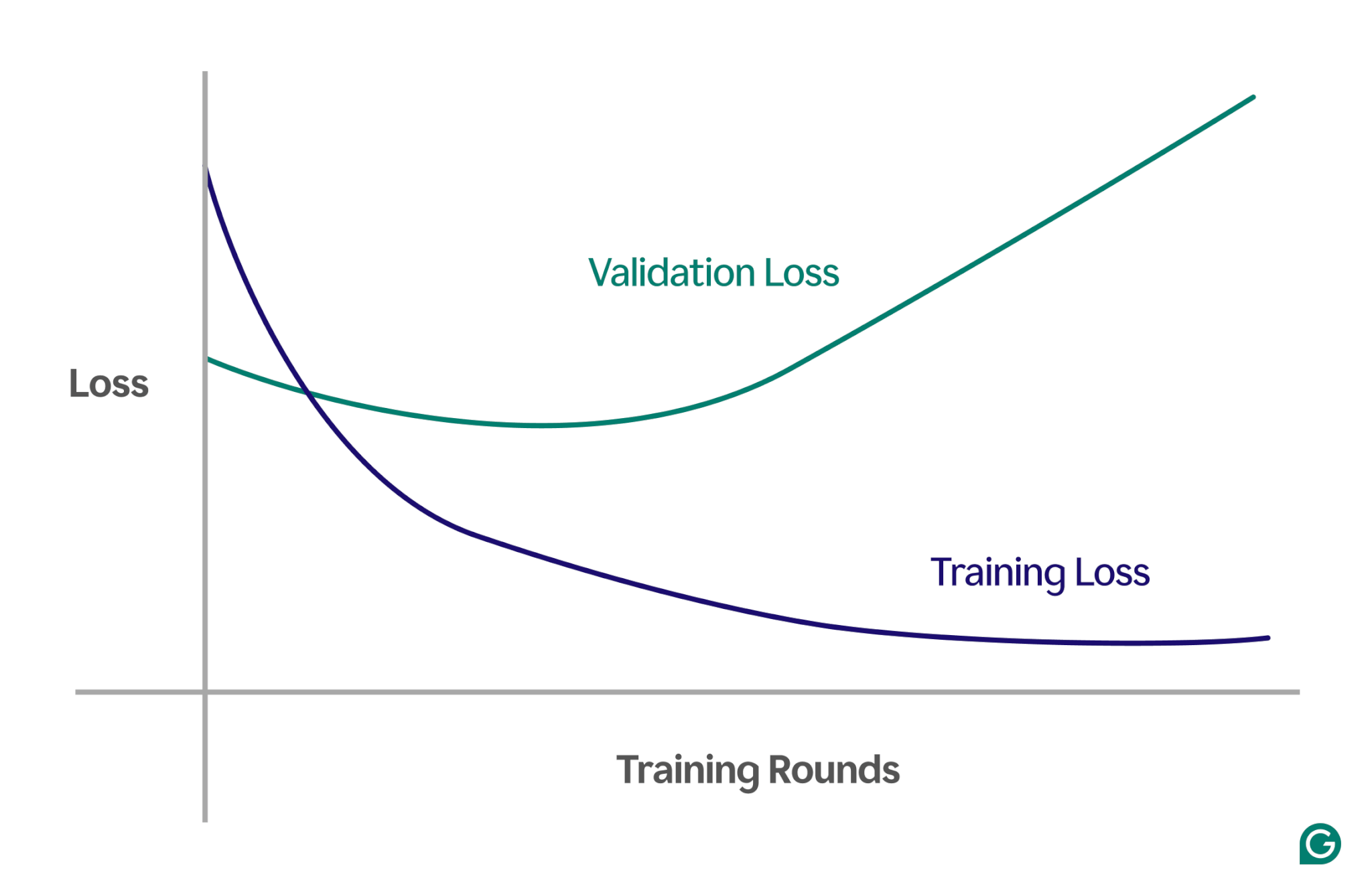
On this state of affairs, whereas the mannequin improves throughout coaching, it performs poorly on unseen knowledge. This seemingly signifies that overfitting has occurred.
The best way to keep away from overfitting
Scale back the mannequin dimension
Regularize the mannequin
Add extra coaching knowledge
Apply dimensionality discount
Statistical strategies, reminiscent of principal element evaluation (PCA), can cut back these correlations. PCA simplifies the information by lowering the variety of dimensions and eradicating correlations, making overfitting much less seemingly. By specializing in essentially the most related options, the mannequin turns into higher at generalizing to new knowledge.



