
What Is Random Forest in Machine Studying?
Random forests are a robust and versatile approach in machine studying (ML). This information will assist you perceive random forests, how they work and their functions, advantages, and challenges.
Desk of contents
What’s a random forest?
A random forest is a machine studying algorithm that makes use of a number of determination timber to make predictions. It’s a supervised studying methodology designed for each classification and regression duties. By combining the outputs of many timber, a random forest improves accuracy, reduces overfitting, and offers extra steady predictions in comparison with a single determination tree.
Resolution timber vs. random forest: What’s the distinction?
Though random forests are constructed on determination timber, the 2 algorithms differ considerably in construction and software:
Resolution timber
A choice tree consists of three predominant parts: a root node, determination nodes (inside nodes), and leaf nodes. Like a flowchart, the choice course of begins on the root node, flows by way of the choice nodes primarily based on situations, and ends at a leaf node representing the result. Whereas determination timber are straightforward to interpret and conceptualize, they’re additionally liable to overfitting, particularly with advanced or noisy datasets.
Random forests
A random forest is an ensemble of determination timber that mixes their outputs for improved predictions. Every tree is skilled on a novel bootstrap pattern (a randomly sampled subset of the unique dataset with substitute) and evaluates determination splits utilizing a randomly chosen subset of options at every node. This strategy, often known as function bagging, introduces variety among the many timber. By aggregating the predictions—utilizing majority voting for classification or averages for regression—random forests produce extra correct and steady outcomes than any single determination tree within the ensemble.
How random forests work
Random forests function by combining a number of determination timber to create a strong and correct prediction mannequin.
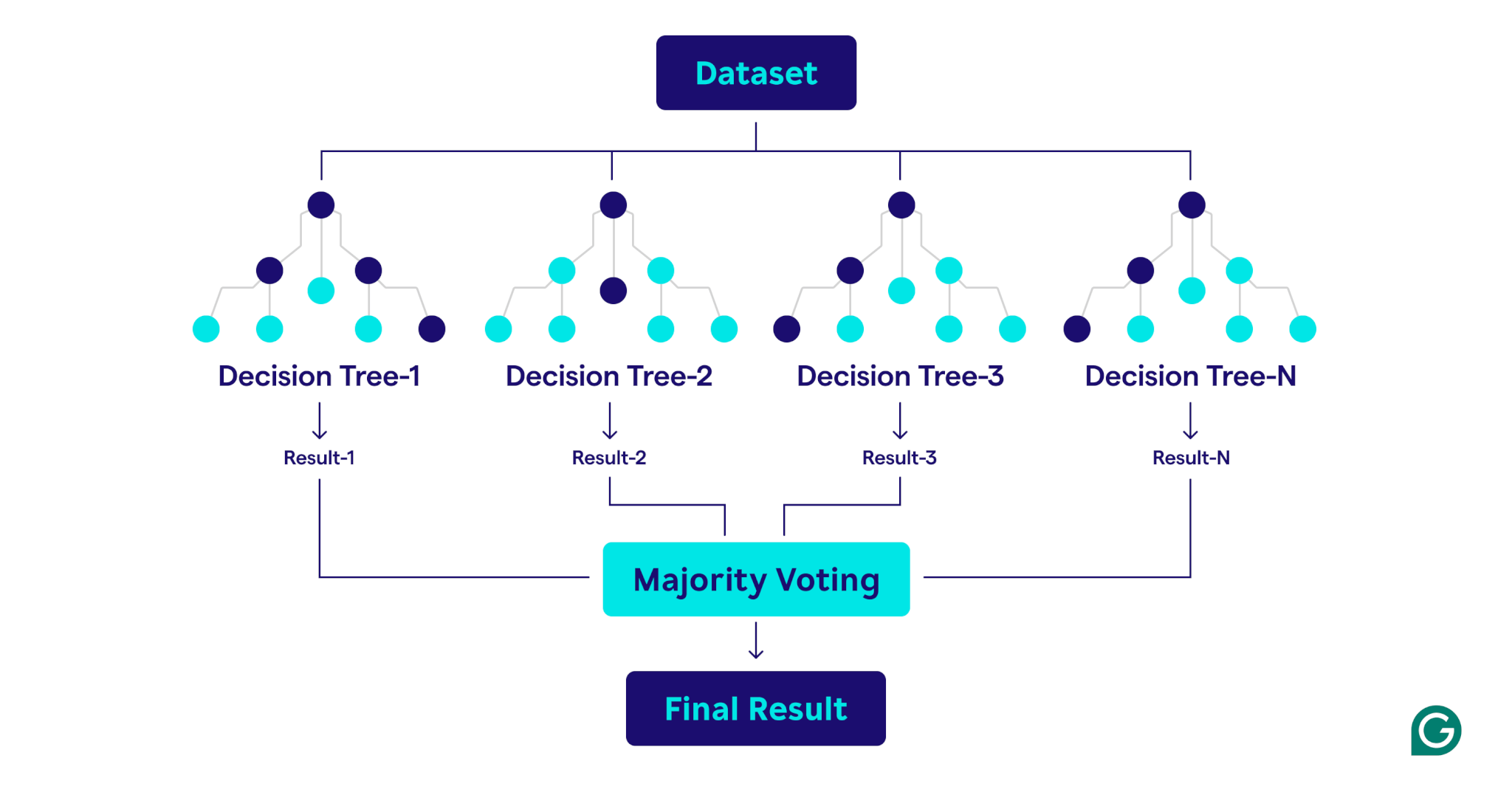
Right here’s a step-by-step clarification of the method:
1. Setting hyperparameters
Step one is to outline the mannequin’s hyperparameters. These embody:
- Variety of timber: Determines the dimensions of the forest
- Most depth for every tree: Controls how deep every determination tree can develop
- Variety of options thought of at every cut up: Limits the variety of options evaluated when creating splits
These hyperparameters enable for fine-tuning the mannequin’s complexity and optimizing efficiency for particular datasets.
2. Bootstrap sampling
As soon as the hyperparameters are set, the coaching course of begins with bootstrap sampling. This includes:
- Knowledge factors from the unique dataset are randomly chosen to create coaching datasets (bootstrap samples) for every determination tree.
- Every bootstrap pattern is often about two-thirds the dimensions of the unique dataset, with some information factors repeated and others excluded.
- The remaining third of the information factors, not included within the bootstrap pattern, is known as the out-of-bag (OOB) information.
3. Constructing determination timber
Every determination tree within the random forest is skilled on its corresponding bootstrap pattern utilizing a novel course of:
- Characteristic bagging: At every cut up, a random subset of options is chosen, guaranteeing variety among the many timber.
- Node splitting: The very best function from the subset is used to separate the node:
- For classification duties, standards like Gini impurity (a measure of how usually a randomly chosen aspect could be incorrectly labeled if it have been randomly labeled in keeping with the distribution of sophistication labels within the node) measure how nicely the cut up separates the lessons.
- For regression duties, methods like variance discount (a way that measures how a lot splitting a node decreases the variance of the goal values, resulting in extra exact predictions) consider how a lot the cut up reduces prediction error.
- The tree grows recursively till it meets stopping situations, resembling a most depth or a minimal variety of information factors per node.
4. Evaluating efficiency
As every tree is constructed, the mannequin’s efficiency is estimated utilizing the OOB information:
- The OOB error estimation offers an unbiased measure of mannequin efficiency, eliminating the necessity for a separate validation dataset.
- By aggregating predictions from all of the timber, the random forest achieves improved accuracy and reduces overfitting in comparison with particular person determination timber.
Sensible functions of random forests
Like the choice timber on which they’re constructed, random forests may be utilized to classification and regression issues in all kinds of sectors, resembling healthcare and finance.
Classifying affected person situations
In healthcare, random forests are used to categorise affected person situations primarily based on info like medical historical past, demographics, and check outcomes. For instance, to foretell whether or not a affected person is more likely to develop a particular situation like diabetes, every determination tree classifies the affected person as in danger or not primarily based on related information, and the random forest makes the ultimate dedication primarily based on a majority vote. This strategy implies that random forests are significantly nicely suited to the advanced, feature-rich datasets present in healthcare.
Predicting mortgage defaults
Banks and main monetary establishments broadly use random forests to find out mortgage eligibility and higher perceive danger. The mannequin makes use of components like earnings and credit score rating to find out danger. As a result of danger is measured as a steady numerical worth, the random forest performs regression as an alternative of classification. Every determination tree, skilled on barely completely different bootstrap samples, outputs a predicted danger rating. Then, the random forest averages the entire particular person predictions, leading to a strong, holistic danger estimate.
Predicting buyer loss
In advertising, random forests are sometimes used to foretell the chance of a buyer discontinuing the usage of a services or products. This includes analyzing buyer conduct patterns, resembling buy frequency and interactions with customer support. By figuring out these patterns, random forests can classify prospects susceptible to leaving. With these insights, firms can take proactive, data-driven steps to retain prospects, resembling providing loyalty applications or focused promotions.
Predicting actual property costs
Random forests can be utilized to foretell actual property costs, which is a regression job. To make the prediction, the random forest makes use of historic information that features components like geographic location, sq. footage, and up to date gross sales within the space. The random forest’s averaging course of ends in a extra dependable and steady value prediction than that of a person determination tree, which is helpful within the extremely unstable actual property markets.
Benefits of random forests
Random forests supply quite a few benefits, together with accuracy, robustness, versatility, and the flexibility to estimate function significance.
Accuracy and robustness
Random forests are extra correct and sturdy than particular person determination timber. That is achieved by combining the outputs of a number of determination timber skilled on completely different bootstrap samples of the unique dataset. The ensuing variety implies that random forests are much less liable to overfitting than particular person determination timber. This ensemble strategy implies that random forests are good at dealing with noisy information, even in advanced datasets.
Versatility
Like the choice timber on which they’re constructed, random forests are extremely versatile. They will deal with each regression and classification duties, making them relevant to a variety of issues. Random forests additionally work nicely with giant, feature-rich datasets and may deal with each numerical and categorical information.
Characteristic significance
Random forests have a built-in capacity to estimate the significance of specific options. As a part of the coaching course of, random forests output a rating that measures how a lot the accuracy of the mannequin adjustments if a selected function is eliminated. By averaging the scores for every function, random forests can present a quantifiable measure of function significance. Much less necessary options can then be eliminated to create extra environment friendly timber and forests.
Disadvantages of random forests
Whereas random forests supply many advantages, they’re tougher to interpret and extra expensive to coach than a single determination tree, they usually might output predictions extra slowly than different fashions.
Complexity
Whereas random forests and determination timber have a lot in frequent, random forests are tougher to interpret and visualize. This complexity arises as a result of random forests use a whole lot or hundreds of determination timber. The “black field” nature of random forests is a critical downside when mannequin explainability is a requirement.
Computational value
Coaching a whole lot or hundreds of determination timber requires rather more processing energy and reminiscence than coaching a single determination tree. When giant datasets are concerned, the computational value may be even increased. This massive useful resource requirement can lead to increased financial value and longer coaching instances. Because of this, random forests will not be sensible in situations like edge computing, the place each computation energy and reminiscence are scarce. Nonetheless, random forests may be parallelized, which will help cut back the computation value.
Slower prediction time
The prediction technique of a random forest includes traversing each tree within the forest and aggregating their outputs, which is inherently slower than utilizing a single mannequin. This course of can lead to slower prediction instances than less complicated fashions like logistic regression or neural networks, particularly for big forests containing deep timber. To be used circumstances the place time is of the essence, resembling high-frequency buying and selling or autonomous autos, this delay may be prohibitive.



